Blog
Insights from the Web Directions AAA 2021
Access All Areas (AAA) is a 2-day online conference published and organised by Web Directions. It is part of a series that covers CSS, Progressive Web Apps (PWAs), JavaScript performance and accessibility – a topic that is becoming more and more important, especially with the ever-increasing digitalisation of our everyday lives.
Sara Soueidan, who herself is very committed to accessibility on the web, was in charge and moderated the event. Her compilation of the lectures positively surprised us: it was not the normal filling of slots. No, all the talks were selected in such a way that they perfectly built on each other.
Accessibility APIs
Adem Cifcioglu started with a talk on Accessibility APIs. First he explained in detail the Accessibility Tree, which is structured as follows:
- Name
- Roles
- States
- Properties
- Relationship
Such a tree contains the contents of an element, the attributes and associated elements as well as the ARIA attributes. However, elements such as button, checkbox, img etc. are not included. In addition, elements can be hidden with aria-hidden="true".
OS Accessibility APIs and Viewers
- Windows
- MSAA/IAccessible2 and UI Automation with Accessibility Insights
- MacOS
- NSAccessibility with Accessibility Inspector for OSX
- Linux/Gnome
- Accessibility Toolkit and Assistive Technology Service Provider Interface
- iOS
- UIAccessibility with Accessibility Inspector for iOS or Safari DevTools
- Android
- AccessibilityNodeInfo and AccessibilityNodeProvider with Chrome DevTools
Semantics
Hidde de Vries explained that HTML does not make statements about the appearance of the page but rather defines the meaning. The semantics in HTML are defined in elements, attributes and values: <elements attributes="value">. HTML also makes no statement about how certain elements should be used. For example, filling out a form can be done by having the browser automatically fill in known fields or by using other assistive technologies such as voice input, etc. However, there are several ways to express the same semantics, e.g. <button> or <div role="button">. You can find more information on how to use HTML semantics in the specification. And some examples of how not to use HTML have been collected in HTMHell.
| CSS | <table> etc. | <ul>, <ol>, <dl> | <h#> | <button> |
|---|---|---|---|---|
| display: flex | ❌ | ✅ | ✅ | ✅ |
| display: grid | ❌ | ✅ | ✅ | ✅ |
| display: block | ❌ [1] | ❌ [2] | ✅ | ✅ |
| display: inline-block | ❌ [1] | ❌ [2] | ✅ | ✅ |
| display: contents | ❌ [1] | ❌ [2] | ❌ | ❌ [3] |
| [1] | (1, 2, 3) treats all cells as a column |
| [2] | (1, 2, 3) recognises dl everywhere |
| [3] | is still triggered when double-clicking |
In addition, lists can lose their semantics if list-style-type: none is set; see also "Fixing" Lists. Other CSS instructions, such as text-transform: uppercase, are interpreted by some screen readers as abbr. More CSS instructions that influence screen readers can be found in CSS Can Influence Screenreaders.
Hidde de Vries ends his talk with a quote from the Open UI organisation:
„We hope to make it unnecessary to reinvent built-in UI controls“
– Open UI
Other goals of Open UI are:
- Component names of documents, as they already exist today
- A common language for describing user interfaces and design systems
- Browser standards for components of web applications
ARIA standard
Gerard K. Cohen gave an introduction to Accessible Rich Internet Applications (ARIA) and showed how the ARIA specification can be used to create custom-fit components. At the beginning of his presentation, he warned of the dangers that ARIA can bring with it. For example, after analysing one million websites in February 2021, WebAIM concluded:
„On homepages with ARIA, on average 41% more errors were detected than on those without ARIA!“
However, the standard is not easy to keep track of, with 70 ARIA roles and 29 interactive (widget) roles:

WAI-ARIA Taxonomy
In addition, ARIA roles do not offer any interactions by themselves, but only describe states and properties that can then be used to define interactions themselves.
Therefore, he strongly advised to follow the five ARIA rules:
Do not use ARIA if you can use HTML instead.
Don’t change the original semantics, e.g., don’t
<a href=“#” role=“button”>Menu</a>
All interactive ARIA roles must be operable with the keyboard.
Do not use role="presentation" or aria-hidden="true" for visible, focusable elements.
All interactive elements must have an accessible name.
Finally, he pointed out the guidance in the Browser and Assistive Technology Support section:
„It is important to test the interoperability of assistive technologies before code … is used in production.“
He also referred to another quote from Mobile and Touch Support:
„Currently, this guide does not specify which examples are compatible with mobile browsers or touch interfaces. While some of the examples include specific features that improve support for mobile and touch interfaces, some ARIA features are not supported by all mobile browsers. In addition, there is not yet a standardised approach to providing touch interactions that work in all mobile browsers.“
Live Regions
Ugi Kutluoglu explained the problems that Live Regions solve and the misconceptions that need to be addressed. Essentially, they are DOM nodes that are intended for notifications and control screen readers mostly via JavaScript.
A Live Region can be easily deployed anywhere in the DOM before content is added:
<div id=”myLiveRegion” class=”visually-hidden”> </div> <div aria-live=”polite” aria-relevant=”text” aria-atomic=”true” id=”myLiveRegion”> <span>Now playing</span> <span id=”song”>Van Morrison - Celtic New Year</span> </div>
Common mistakes are
- trying to create a language interface
- the assumption that everything is announced in a known way
- assuming that whole sections will become live
- competing live regions
- attempts to communicate the status of live regions
- too many updates in too short a time
To be able to analyse these errors, he presented various debugging tools:
Add a break on subtree modifications to see what gets added, when and by which script
Mutation Observer
(()=>{ const target = document.querySelector('body'); const observer = new MutationObserver(function(mutations) { mutations.forEach((mutation) => { console.log(mutation.addedNodes, mutation.removedNodes, mutation.attributeName) }); }); observer.observe(target, {childList: true,attributes: true,subtree: true}); })();
High contrast mode
Kilian Valkhof made it clear right at the beginning that this mode does not directly lead to higher contrasts but rather reduces the number of colours and that the colours can be selected by the viewer. This makes it easier for people with impaired vision, colour blindness and sensitivity to light, but also in bright sunlight etc., altogether about 4% of those who want to look at a website.

After selecting an option, the Windows High contrast page displays a preview.
Media queries
Typical media query statements might look like this:
@media (forced-colors: active) { } @media (prefers-color-scheme: dark) { } @media (prefers-color-scheme: light) { }
Tips
You should note that you do not usually visualise meanings using colours alone, see Better Form Design.
Alternatively, you can force the colours you have defined to remain:
element { forced-colors-adjust: none; }
For images, you should specify a dark and a light mode in the <picture> tag and in SVGs a <style> element.
For focus elements, the colours selected in high-contrast mode should also be displayed, if necessary. For example, outline: none; should not be used but instead:
element:focus { outline-color: transparent; box-shadow: 0 0 0 2px orangered; }
Colour contrast and WCAG
- Todd Libby’s presentation was really about colour
- contrast and how to meet the WCAG 2.0 success criteria. He illustrated this with some success criteria:
- Success Criterion 1.4.6 Contrast (Enhanced) (AAA)
The visual representation of text and text in images shall have a contrast ratio of at least 7:1 except for the following:
- Large text and images with large text have a contrast ratio of at least 4.5:1
- Incidental text and text in images that are part of an inactive component of the user interface, or that are purely decorative, or that are not visible to visible to anyone, or that are part of an image that includes significant other visual content, do not have contrast requirements.
- Logotypes, text that is part of a logo or brand name, does not have to have contrast.
- Success Criterion 1.4.11 Non-text Contrast (AA)
The visual representation of the following components shall have a contrast ratio of at least 3:1 to adjacent colours:
- User interface components
- Visual information required to identify user interface components and states of the user interface, except in the case of inactive components or if the appearance of the component is determined by the user agent and not changed by the author.
- Graphical objects
- Portions of graphics that are necessary to understand the content, unless a particular representation of graphics is essential to the information to be conveyed.
Unfortunately, colour contrasts are still one of the most common errors on websites in 2021 in terms of accessibility:
86.4% of homepages contained low-contrast text, an average of 31 instances per homepage.
– WebAIM Million – 2021 Update
Thereby there are several tools that can be used to check colour contrasts:
- contrast ratio
- Who can use
- Contrast Checker
- Colour Contrast Checker
- Randoma11y
- Button Contrast Checker
There are also several browser extensions available:
And entire colour palettes can also be tested:
Finally, he gave the tip that colour ratios should keep to the minimum contrasts, but at the same time too strong contrasts in the text can lead to a blurred perception.
Accessible SVGs
Heather Migliorisi reported on scalable vector graphics (SVG), which are increasingly becoming the preferred graphics format on the web. This also has an impact on assistive technologies. Her 2021 updated article Accessible SVGs describes in details the topics of her talk, so we don’t need to summarise it here ourselves. However, she recommended a few additional sources:
- Carie Fisher: Creating Accessible SVGs
- Sara Soueidan: Accessible Icon Buttons
- An alt Decision Tree
- Sarah Higley: Quick Tips for High Contrast Mode
- Melanie Richards: CurrentColor SVG in forced colors modes
- Val Head: Designing With Reduced Motion For Motion Sensitivities
Making movement inclusive
Val Head emphasised the preference for reduced movements:

Most of the browsers n use also support the Media Query prefers-reduced-motion:

The media query can be implemented in CSS as well as in Javascript:
@media (prefers-reduced-motion: reduce) { }
const motionQuery = window.matchMedia('(prefers-reduced-motion)'); if (motionQuery.matches) { document.documentElement.classList.add('reduced-motion'); } motionQuery.addListener(handleReduceMotionChanged); handleReduceMotionChanged();
She then showed how interface animations can be designed accordingly. Among other things, she showed Animation with reduced-motion by Marcy Sutton.
For more information on the preference for reduced motion, see her book Designing Interface Animation, the WebKit article Responsive Design for Motion and her article Designing With Reduced Motion For Motion Sensitivities.
Get in touch
In our training courses, we give a practical introduction to the appropriate technologies for accessible websites. We will also be happy to provide you with an individual offer for the development of your style guide or your frontend, into which we will integrate the latest findings.

I also like to call back!
Find data and its origin with DataHub
Traditionally, this function has been provided by bloated data cataloguing solutions. In recent years, a number of open source projects have emerged that improve the developer experience (DX) of both providing and consuming data, e.g. Netflix’s Metacat, LinkedIn’s WhereHows, LF AI & Data Foundation’s Amundsen and WeWork’s Marquez. At the same time, the behaviour of data providers also changed, moving away from bloated data cataloguing solutions towards tools that can derive partial metadata information from different sources.
LinkedIn has also developed WhereHows into DataHub. This platform enables data to be found via an extensible metadata system. Instead of crawling and polling metadata, DataHub uses a push model where the individual components of the data ecosystem publish metadata to the central platform via a REST API or a Kafka stream. This push-based integration shifts responsibility from the central entity to the individual teams, who are thus responsible for their metadata. As more and more companies seek to become data-driven, a system that helps with data discovery and understanding data quality and provenance is critical.
The Generalised Metadata Architecture (GMA) of DataHub allows different storage technologies that can be requested with
- document-based CRUD (Create, Read, Update, Delete)
- complex queries even of nested tables
- graph traversal
- full text search incl. auto-completion
Plugins are available for files, BigQuery, dbt, Hive, Kafka, LDAP, MongoDB, MySQL, PostgreSQL, SQLAlchemy, and Snowflake, among others. You can also transfer metadata to the DataHub via console, REST API and files.
With the GMA, each team can also provide its own metadata services, so-called GMS, to make their data accessible via graphs and search indexes.
In order to also be able to open up the software that was used to create the data, we currently use Git2PROV and then import the W3C PROV data with the file sink.
Finally, DataHub uses Apache Gobblin to open up the data lifecycle.
How better developer experience increases productivity
According to State of DevOps 2021, in 78 percent of organisations, DevOps implementation is stalled at a medium level. This percentage has remained almost the same for 4 years.

The vast majority of companies are stuck in mid-level DevOps development. The study divided the mid-level into three categories to explore the phenomenon in more detail.
Unsurprisingly, companies that are already well advanced in DevOps implementation have also automated the most processes. These companies also have the most top-down support for the bottom-up change (→ Top-down and bottom-up design):
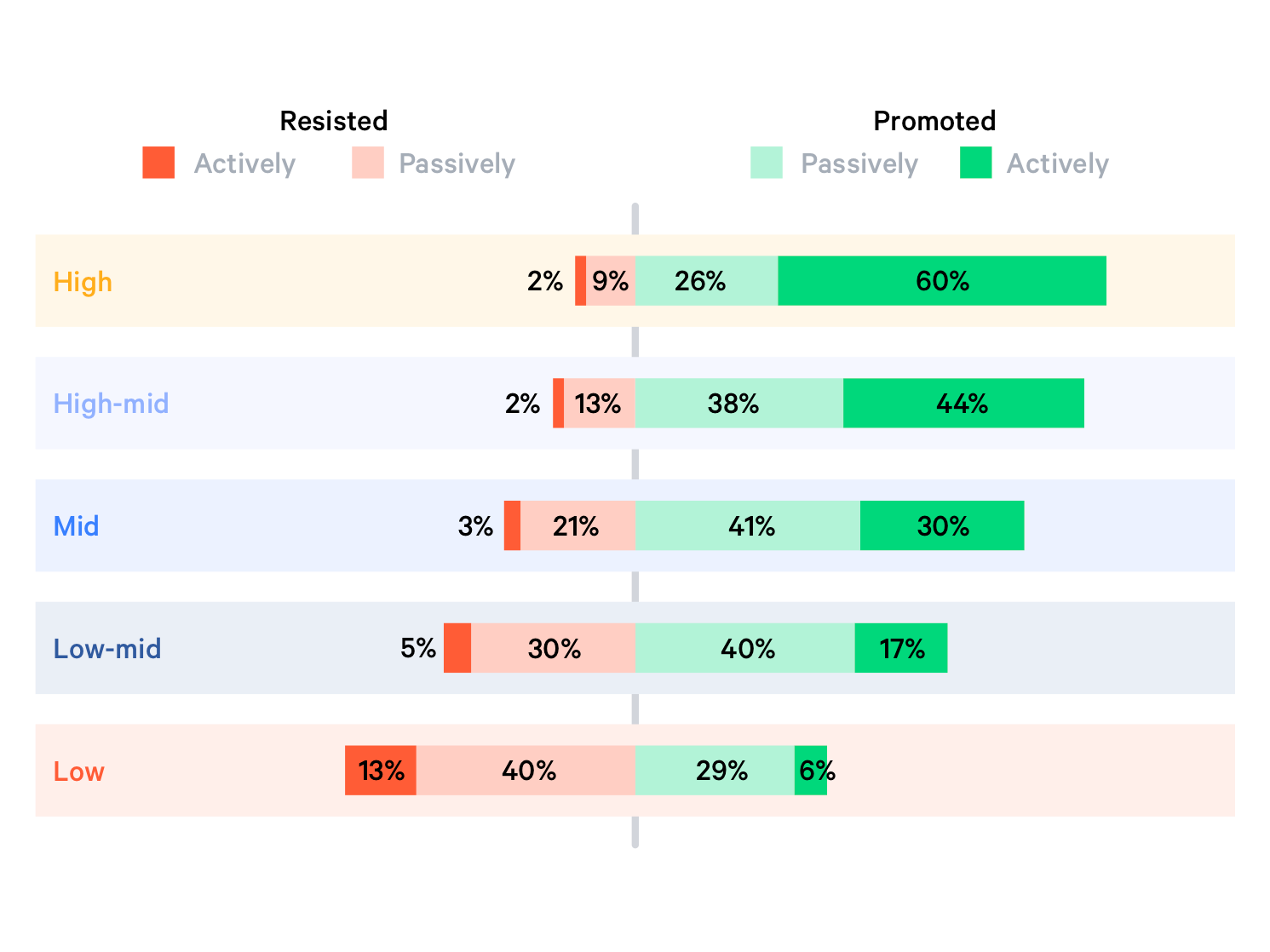
Less than 2 percent of employees at highly developed companies report resistance to DevOps at the executive level, and the figure is also only 3 percent at medium-developed companies. However, only 30 percent report that DevOps is actively promoted, compared to 60 percent of highly developed companies.
A definition of DevOps suggests the reasons why many companies are stuck in implementation:
DevOps is the philosophy of unifying development and operations at the levels of culture, practice and tools to achieve faster and more frequent deployment of changes to production.
– Rob England: Define DevOps: What is DevOps?, 2014
A key aspect of DevOps culture is shared ownership of the system. It is easy for a development team to lose interest in operations and maintenance when it is handed over to another team to run. However, when the development team shares responsibility for the operation of a system throughout its lifecycle, it can better understand the problems faced by the operations team and also find ways to simplify deployment and maintenance, for example by automating deployments (→ Release, → Deploy) and improving monitoring (→ Metrics, → Incident Management, → Status page, ). Conversely, when the operations team shares responsibility for a system, they work more closely with the development team, which then has a better understanding of operational requirements.

DevOps changes
Organisational changes are needed to support a culture of shared responsibility. Development and operations shouldn’t be silos. Those responsible for operations should be involved in the development team at an early stage. Collaboration between development and operations helps with cooperation. Handoffs and releases, on the other hand, discourage, hinder shared responsibility, and encourage finger-pointing.
To work together effectively, the development and operations teams must be able to make decisions and changes. This requires trust in these autonomous teams, because only then will their approach to risk change and an environment be created that is free from fear of failure.
Feedback is essential to foster collaboration between the development team and operations staff and to continuously improve the system itself. The type of feedback can vary greatly in duration and frequency:
- Reviewing one’s own code changes should be very frequent and therefore only take a few seconds
- However, checking whether a component can be integrated with all others can take several hours and will therefore be done much less frequently.
- Checking non-functional requirements such as timing, resource consumption, maintainability etc. can also take a whole day.
- The team’s response to a technical question should not take hours or even weeks.
- The time until new team members become productive can take weeks or even months.
- Until a new service can become productive should be possible within a few days.
- However, finding errors in productive systems is often only successful after one or more days.
- A first confirmation by the target group that a change in production is accepted should be possible after a few weeks.
It should be self-explanatory that feedback loops are carried out more often when they are shorter. Early and frequent validation will also reduce later analysis and rework. Feedback loops that are easy to interpret also reduce effort significantly.
Etsy not only records whether the availability and error rate of components meet its own requirements, but also to what extent a functional change is accepted by the target group: if a change turns out to be worthless, it is removed again, thus reducing technical debt.
Developer Experience
Developer Experience (DX), which applies concepts from UX optimisation to experiences in development teams, can be a good addition here to better capture the cultural level from the development team’s perspective. In Developer Experience: Concept and Definition Fabian Fagerholm and Jürgen Münch distinguish the following three aspects:
| Aspect | Description | Topics |
|---|---|---|
| cognition | How do developers perceive the development infrastructure? |
|
| affect | How do developers feel about their work? |
|
| conation | How do developers see the value of their contribution? |
|
This is what the day might look like for members of the development team in a less effective environment:
- The day starts with a series of problems in production.
- Since there are no aggregated evaluations, the error is searched for in various log files and monitoring services.
- Finally, the problem is suspected to be swapping out memory to a swap file and the operations team is asked for more memory.
- Now it’s finally time to see if there was any feedback from the QA team on the newly implemented function.
- Then it’s already the first of several status meetings.
- Finally, development could begin, if only access to the necessary API had already been provided. Instead, phone calls are now being made to the team that provides access to the API so that we can’t start work for several days.
We could list many more blockages; in the end, the members of the development team end their working day frustrated and demotivated. Everything takes longer than it should and the day consists of never-ending obstacles and bureaucracy. Not only do development team members feel ineffective and unproductive. When they eventually accept this way of working, learned helplessness spreads among them.
In such an environment, companies usually try to measure productivity and identify the lowest performing team members by measuring the number of code changes and tickets successfully processed. In such companies, in my experience, the best professionals will leave; there is no reason for them to remain in an ineffective environment when innovative digital companies are looking for strong technical talents.
The working day in a highly effective work environment, on the other hand, might look like this:
- The day starts by looking at the team’s project management tool, e.g. a so-called Kanban board, then there is a short standup meeting after each team member is clear on what they will be working on today.
- The team member notes that the development environment has automatically received up-to-date libraries, which have also already been transferred to production as all CI/CD pipelines were green.
- Next, the changes are applied to their own development environment and the first incremental code changes are started, which can be quickly validated through unit testing.
- The next feature requires access to the API of a service for which another team is responsible. Access can be requested via a central service portal, and questions that arise are quickly answered in a chat room.
- Now the new feature can be worked on intensively for several hours without interruption.
- After the feature has been implemented and all component tests have been passed, automated tests check whether the component continues to integrate with all other components.
- Once all Continuous Integration pipelines are green, the changes are gradually released to the intended target groups in production while monitoring operational metrics.
Each member of such a development team can make incremental progress in a day and end the workday satisfied with what has been achieved. In such a work environment, work objectives can be achieved easily and efficiently and there is little friction. Team members spend most of their time creating something valuable. Being productive motivates development team members. Without friction, hey have time to think creatively and apply themselves. This is where companies focus on providing an effective technical environment.
Get in touch
We will be happy to answer your questions and create a customised offer for the DevOps transformation.
I also like to call you back!
Criteria for safe and sustainable software
- Open Source
- The best way to check how secure your data is against unauthorised access is to use open source software.
- Virtual Private Network
- This is usually the basis for accessing a company network from outside. However, do not blindly trust the often false promises of VPN providers, but use open source programmes such as OpenVPN or WireGuard.
- Remote desktop software
- Remotely is a good open source alternative to TeamViewer or AnyDesk.
- Configuration
Even with open-source software, check whether the default settings are really privacy-friendly:
For example, Jitsi Meet creates external connections to gravatar.com and logs far too much information with the INFO logging level. Previous Jitsi apps also tied in the trackers Google CrashLytics, Google Firebase Analytics and Amplitude. Run your own STUN servers if possible, otherwise meet-jit-si-turnrelay.jitsi.net is used.
- Encryption methods
Here you should distinguish between transport encryption – ideally end-to-end – and encryption of stored data.
The synchronisation software Syncthing, for example, uses both TLS and Perfect Forward Secrecy to protect communication.
You should be informed if the fingerprint of a key changes.
- Metadata
- Make sure that communication software avoids or at least protects metadata; it can tell a lot about users’ lives.
- Audits
- Even the security risks of open source software can only be detected by experts. Use software that has successfully passed a security audit.
- Tracker
Smartphone apps often integrate a lot of trackers that pass on data to third parties such as Google or Facebook without the user’s knowledge. εxodus Privacy is a website that analyses Android apps and shows which trackers are included in an app.
It also checks whether the permissions requested by an app fit the intended use. For example, it is incomprehensible why messengers such as Signal, Telegram and WhatsApp compulsorily require the entry of one’s own telephone number.
- Malvertising
Avoid apps that embed advertising and thus pose the risk of malicious code advertising. Furthermore, tracking companies can evaluate and market the activities of users via embedded advertising.
There are numerous tools such as uBlock Origin for Firefox, Blokada for Android and iOS or AdGuard Pro for iOS that prevent the delivery of advertising and the leakage of personal data. With HttpCanary for Android apps and Charles Proxy for iOS apps, users can investigate for themselves how apps behave unless the app developers resort to certificate pinning. Burp Suite intercepts much more than just data packets and can also bypass certificate pinning.
- Decentralised data storage
- It is safest if data is stored decentrally. If this is not possible, federated systems, such as email infrastructure, are preferable to centralised ones.
- Financial transparency
- If there are companies behind open source software, they should be transparent about their finances and financial interests in the software. A good example in this respect is Delta Chat.
- Availability
- If an Android app is available, for example, only via Google's Play Store or also via the more privacy-friendly F-Droid Store.
- Data economy
- When selecting software, check not only whether it meets all functional requirements, but also whether it stores only the necessary data.
- Data synchronisation
- Data from a software should be able to be synchronised between multiple devices without the need for a central server to mediate it. For example, we sync our KeePass database directly between our devices using Syncthing and not via WebDAV or Nextcloud. This means that password data is not cached anywhere, but only stored where it is needed.
- Backup
- To ensure that all relevant data is securely available for the entire period of use, backup copies should be made. These should be stored in a safe place that is also legally permissible. The backup should also be automatic and the backups should be encrypted.
Python Pattern Matching in Admin Magazine #63
The originally object-oriented programming language Python is to receive a new feature in version 3.10, which is mainly known from functional languages: pattern matching. The change is controversial in the Python community and has triggered a heated debate.
Pattern matching is a symbol-processing method that uses a pattern to identify discrete structures or subsets, e.g. strings, trees or graphs. This procedure is found in functional or logical programming languages where a match expression is used to process data based on its structure, e.g. in Scala, Rust and F#. A match statement takes an expression and compares it to successive patterns specified as one or more cases. This is superficially similar to a switch statement in C, Java or JavaScript, but much more powerful.
Python 3.10 is now also to receive such a match expression. The implementation is described in PEP (Python Enhancement Proposal) 634. [1] Further information on the plans can be found in PEP 635 [2] and PEP 636 [3]. How pattern matching is supposed to work in Python 3.10 is shown by this very simple example, where a value is compared with several literals:
def http_error(status):
match status:
case 400:
return "Bad request"
case 401:
return "Unauthorized"
case 403:
return "Forbidden"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something else"
In the last case of the match statement, an underscore _ acts as a placeholder that intercepts everything. This has caused irritation among developers because an underscore is usually used in Python before variable names to declare them for internal use. While Python does not distinguish between private and public variables as strictly as Java does, it is still a very widely used convention that is also specified in the Style Guide for Python Code [4].
However, the proposed match statement can not only check patterns, i.e. detect a match between the value of a variable and a given pattern, it also rebinds the variables that match the given pattern.
This leads to the fact that in Python we suddenly have to deal with Schrödinger constants, which only remain constant until we take a closer look at them in a match statement. The following example is intended to explain this:
NOT_FOUND = 404
retcode = 200
match retcode:
case NOT_FOUND:
print('not found')
print(f"Current value of {NOT_FOUND=}")
This results in the following output:
not found Current value of NOT_FOUND=200
This behaviour leads to harsh criticism of the proposal from experienced Python developers such as Brandon Rhodes, author of «Foundations of Python Network Programming»:
If this poorly-designed feature is really added to Python, we lose a principle I’ve always taught students: “if you see an undocumented constant, you can always name it without changing the code’s meaning.” The Substitution Principle, learned in algebra? It’ll no longer apply.
— Brandon Rhodes on 12 February 2021, 2:55 pm on Twitter [5]
Many long-time Python developers, however, are not only grumbling about the structural pattern-matching that is to come in Python 3.10. They generally regret developments in recent years in which more and more syntactic sugar has been sprinkled over the language. Original principles, as laid down in the Zen of Python [6], would be forgotten and functional stability would be lost.
Although Python has defined a sophisticated process with the Python Enhancement Proposals (PEPs) [7] that can be used to collaboratively steer the further development of Python, there is always criticism on Twitter and other social media, as is the case now with structural pattern matching. In fact, the topic has already been discussed intensively in the Python community. The Python Steering Council [8] recommended adoption of the Proposals as early as December 2020. Nevertheless, the topic only really boiled up with the adoption of the Proposals. The reason for this is surely the size and diversity of the Python community. Most programmers are probably only interested in discussions about extensions that solve their own problems. The other developments are overlooked until the PEPs are accepted. This is probably the case with structural pattern matching. It opens up solutions to problems that were hardly possible in Python before. For example, it allows data scientists to write matching parsers and compilers for which they previously had to resort to functional or logical programming languages.
With the adoption of the PEP, the discussion has now been taken into the wider Python community. Incidentally, Brett Cannon, a member of the Python Steering Council, pointed out in an interview [9] that the last word has not yet been spoken: until the first beta version, there is still time for changes if problems arise in practically used code. He also held out the possibility of changing the meaning of _ once again.
So maybe we will be spared Schrödinger’s constants.
| [1] | PEP 634: Specification |
| [2] | PEP 635: Motivation and Rationale |
| [3] | PEP 636: Tutorial |
| [4] | https://pep8.org/#descriptive-naming-styles |
| [5] | @brandon_rhodes |
| [6] | PEP 20 – The Zen of Python |
| [7] | Index of Python Enhancement Proposals (PEPs) |
| [8] | Python Steering Council |
| [9] | Python Bytes Episode #221 |
On the return of Richard Stallman to the board of the Free Software Foundation
In 2019, Stallman was forced to resign from his board position at the FSF as well as his position at MIT due to public pressure following his controversial comments on the Jeffrey Epstein child trafficking scandal. At the time, we hoped that the opportunity created by his resignation would be used by the Free Software Foundation to transform itself into a diverse and inclusive organisation. Unfortunately, the FSF has taken few steps in this direction. Richard Stallman’s return now dashed our hopes for the time being, and the Board’s preliminary statement also sounds less than credible to us.
Stallman himself was allowed to announce his return to the board of the Free Software Foundation:
Some of you will be happy at this, and some might be disappointed but who knows. In any case, that’s how it is and I’m not planning to resign a second time.
– Richard Stallman at LibrePlanet 2021 [1]
On its website, however, the FSF emphasises:
Free software is only as successful as the communities that create, use, support, and advocate for it.
It is overtly clear that the FSF must change fundamentally and permanently to regain the squandered trust of the free software movement and to fulfil its statutory, public good mission.
| [1] | Video |
Security gaps and other incalculable risks at Microsoft – time to switch to open source
Multiple critical vulnerabilities in Microsoft Exchange servers
The German Federal Office for Information Security (BSI) rates the current vulnerabilities in MS Exchange as a business-critical IT threat situation with massive impairments of regular operations [1]. But that is not enough:
«In many infrastructures, Exchange servers have a large number of permissions in the Active Directory by default (sometimes unjustified). It is conceivable that further attacks with the rights of a taken-over Exchange server could potentially compromise the entire domain with little effort. It must also be taken into account that the vulnerability could also be exploited from the local network if, for example, an attacker gains access to Outlook Web Access via an infected client.»
– BSI: Mehrere Schwachstellen in MS Exchange, 17.03.2021
The Computer Emergency Response Team of the Federal Administration (CERT-Bund) considers a compromise of an Outlook Web Access server (OWA) accessible from the Internet to be probable as of 26 February [2]. If admins now apply the security patches, the known security gaps will be closed, but a possible malware will not be eliminated. In addition, it is necessary to check whether servers in the domain have already been the target of such an attack and, for example, whether backdoors have already been opened.
Even today, about 12,000 of 56,000 Exchange servers with open OWA in Germany are said to be vulnerable to ProxyLogon [3] and another 9,000 Exchange servers have been taken offline or prevented from accessing OWA from the Internet in the last two weeks [4]:

Source: CERT-Bund
Only a month ago, the CERT-Bund warned that even one year after the release of the security update, 31-63% of Exchange servers in Germany with OWA openly accessible from the internet were still vulnerable to the critical vulnerability CVE-2020-0688 [5].
Problems also with Microsoft 365 and Azure Cloud
Several Microsoft services failed on the evening of 15 March 2021. The problems were caused by an automatically deleted key in the Azure Active Directory (AAD). This prevented users from logging in for hours. This also affected other services that are based on the Azure Cloud, including Microsoft Teams, XBox Streams and Microsoft Dynamics. In September 2020 and February 2019, there were already outages of Microsoft cloud services lasting several hours, which were also due to errors in the Azure Active Directory Service (AAD) [6].
However, these were by no means the only problems with Microsoft 365 and the Azure Cloud: according to a study by Sapio Research on behalf of Vectra AI [7] of 1,112 IT security decision-makers in companies that use Office 365 and have more than a thousand employees, attackers can take over Office 365 accounts in most companies.
The reason for the study was that remote working has become normal as a result of the global Corona pandemic and companies have quickly moved to the cloud. Office 365 has been a common choice. However, with 258 million users, they have also become a tempting target for cyber attacks. According to the survey, in the last 12 months
- 82% have experienced an increased security risk to their organisation
- 70% have seen the takeover of accounts of authorised users, with an average of seven accounts hijacked
- 58% have seen a widening gap between the capabilities of attackers and defenders.
Most respondents see a growing threat in moving data to the cloud. Above all, the effort required to secure the infrastructure was initially underestimated.
Microsoft vs. privacy
Finally, the State Commissioner for Data Protection in Mecklenburg-Western Pomerania and the State Audit Office are now demanding that the state government stop using Microsoft products with immediate effect:
«Among others, products of the company Microsoft are affected. However, a legally compliant use of these products solely on the basis of standard data protection clauses is not possible due to the principles established by the European Court of Justice. Without further security measures, personal data would be transmitted to servers located in the USA.»
– Press release of the State Commissioner for Data Protection and Freedom of Information Mecklenburg-Western Pomerania, 17.03.2021 [8].
In fact, however, this demand does not come as a surprise: The Conference of the Independent Data Protection Authorities of the Federation and the States already pointed out these dangers in 2015 [9].
Consequently, the State Audit Office of Mecklenburg-Western Pomerania concludes that software that cannot be used in compliance with the law cannot be operated economically.
Outlook
The news of the last few days make it clear that Microsoft can be operated neither securely nor reliably even if the operating costs were significantly increased. Finally, Microsoft services are not likely to be used in a legally compliant manner in Europe. With open source alternatives, more transparency, security and digital sovereignty could be achieved again. For example, last year we began advising a large German research institution on alternatives to Microsoft 365: Microsoft alternatives – migration to open source technologies. In the process, we are gradually replacing Microsoft products with OpenSource products over several years.
Update: 13 April 2021
There are again vulnerabilities in Microsoft Exchange Server, for which Microsoft has published updates for Exchange Server as part of its patch day [10]. This should be installed immediately. The BSI considers this to be a security vulnerability with increased monitoring of anomalies with temporary impairment of regular operation [11].
Update: 23. Juli 2021
In the press release, the State Commissioner for Data Protection of Lower Saxony, Barbara Thiel, continues to be critical of the use of Microsoft 365:
«We have not yet issued a corresponding order or prohibition, but it is true that we regard the use of these products as very critical. … Due to the overall situation described I can still only strongly advise against the use of Office 365 from the data protection perspective.»
– Press release of the State Commissioner for Data Protection of Lower Saxony, Barbara Thiel, 22 July 2021 [12]
Get in touch
I will be happy to answer your questions and create a customised offer for the migration from Microsoft 365 to OpenSource alternatives.
I will also be happy to call you!
| [1] | BSI: Mehrere Schwachstellen in MS Exchange |
| [2] | @certbund, 6 Mar. 2021 |
| [3] | ProxyLogon |
| [4] | @certbund 17 Mar. 2021 |
| [5] | @certbund, 9 Feb. 2021 |
| [6] | Microsoft-Dienste fielen wegen Authentifizierungs-Fehler aus |
| [7] | IT Security Changes Amidst the Pandemic. Office 365 research amongst 1,112 enterprises worldwide |
| [8] | Pressemitteilung des Landesbeauftragten für Datenschutz und Informationsfreiheit Mecklenburg-Vorpommern, 17.03.2021 |
| [9] | 90. Konferenz der Datenschutzbeauftragten des Bundes und der Länder: Cloud-unterstützte Betriebssysteme bergen Datenschutzrisiken, 01.10.2015 |
| [10] | Microsoft Security Response Center: April 2021 Update Tuesday packages now available |
| [11] | BSI: Neue Schwachstellen in Microsoft Exchange Server |
| [12] | Thiel: Einsatz von Office 365 weiter kritisch – Verantwortliche müssen datenschutzkonforme Kommunikationsstrukturen etablieren |
Choosing the right NoSQL database
NoSQL databases should solve the following problems:
- Bridging the internal data structure of the application and the relational data structure of the database.
- Moving away from the integration of a wide variety of data structures into a uniform data model.
- The growing amount of data increasingly required clusters for data storage
Aggregated data models
Relational database modelling is very different from the types of data structures that application developers use. The use of data structures modelled by developers to solve different problem domains has led to a move away from relational modelling towards aggregate models. Most of this is inspired by Domain Driven Design. An aggregate is a collection of data that we interact with as a unit. These aggregates form the boundaries for ACID operations, where Key Values, Documents and Column Family can be seen as forms of an aggregator-oriented database.
Aggregates make it easier for the database to manage data storage on a cluster, as the data unit can now be on any computer. Aggregator-oriented databases work best when most data interactions are performed with the same aggregate, e.g. when a profile needs to be retrieved with all its details. It is better to store the profile as an aggregation object and use these aggregates to retrieve profile details.
Distribution models
Aggregator-oriented databases facilitate the distribution of data because the distribution mechanism only has to move the aggregate and doesn’t have to worry about related data, since all related data is contained in the aggregate itself. There are two main types of data distribution:
- Sharding
- Sharding distributes different data across multiple servers so that each server acts as a single source for a subset of data.
- Replication
Replication copies data across multiple servers so that the same data can be found in multiple locations. Replication takes two forms:
Master-slave replication makes one node the authoritative copy, processing writes, while slaves are synchronised with the master and may process reads.
Peer-to-peer replication allows writes to any node. Nodes coordinate to synchronise their copies of the data.
Master-slave replication reduces the likelihood of update conflicts, but peer-to-peer replication avoids writing all operations to a single server, thus avoiding a single point of failure. A system can use one or both techniques.
CAP Theorem
In distributed systems, the following three aspects are important:
- Consistency
- Availability
- Partition tolerance
Eric Brewer has established the CAP theorem, which states that in any distributed system we can only choose two of the three options. Many NoSQL databases try to provide options where a setup can be chosen to set up the database according to your requirements. For example, if you consider Riak as a distributed key-value database, there are essentially the three variables
- r
- Number of nodes to respond to a read request before it is considered successful
- w
- number of nodes to respond to a write request before it is considered successful
- n
- Number of nodes on which the data is replicated, also called replication factor
In a Riak cluster with 5 nodes, we can adjust the values for r, w and n so that the system is very consistent by setting r = 5 and w = 5. However, by doing this we have made the cluster vulnerable to network partitions, as no write is possible if only one node is not responding. We can make the same cluster highly available for writes or reads by setting r = 1 and w = 1. However, now consistency may be affected as some nodes may not have the latest copy of the data. The CAP theorem states that when you get a network partition, you have to balance the availability of data against the consistency of data. Durability can also be weighed against latency, especially if you want to survive failures with replicated data.
Often with relational databases you needed little understanding of these requirements; now they become important again. So you may have been used to using transactions in relational databases. In NoSQL databases, however, these are no longer available to you and you have to think about how they should be implemented. Does the writing have to be transaction-safe? Or is it acceptable for data to be lost from time to time? Finally, sometimes an external transaction manager like ZooKeeper can be helpful.
Different types of NoSQL databases
NoSQL databases can be roughly divided into four types:
Key-value databases
Key-value databases are the simplest NoSQL data stores from an API perspective. The client can either retrieve the value for the key, enter a value for a key or delete a key from the data store. The value is a blob that the datastore just stores without caring or knowing what is inside. It is solely the responsibility of the application to understand what has been stored. Because key-value databases always use primary key access, they generally have high performance and can be easily scaled.
Some of the most popular key-value databases are
- Riak KV
- Home | GitHub | Docs
- Redis
- Home | GitHub | Docs
- Memcached
- Home | GitHub | Docs
- Berkeley DB
- Home | GitHub | Docs
- Upscaledb
- Home | GitHub | C API Docs
You need to choose them carefully as there are big differences between them. For example, while Riak stores data persistently, Memcached usually does not.
Document databases
These databases store and retrieve documents, which may be XML, JSON, BSON, etc. These documents are hierarchical tree data structures that can consist of maps, collections and scalar values. Document databases provide rich query languages and constructs such as databases, indexes, etc. that allow for an easier transition from relational databases.
Some of the most popular document databases are
Column Family Stores
These databases store data in column families as rows assigned to a row key. They are excellent for groups of related data that are frequently accessed together. For example, this could be all of a person’s profile information, but not their activities.
While each Column Family can be compared to the row in an RDBMS table where the key identifies the row and the row consists of multiple columns, in Column Family Stores the different rows do not have to have the same columns.
Some of the most popular Column Family Stores are
Cassandra can be described as fast and easily scalable because writes are distributed across the cluster. The cluster does not have a master node, so reads and writes can be performed by any node in the cluster.
Graph database
In graph databases you can store entities with certain properties and relationships between these entities. Entities are also called nodes. Think of a node as an instance of an object in an application; relationships can then be called edges, which can also have properties and are directed.
Graph models
- Labeled Property Graph
- In a labelled property graph, both nodes and edges can have properties.
- Resource Description Framework (RDF)
- In RDF, graphs are represented using triples. A triple consists of three elements in the form node-edge-node subject --predicate-> object, which are defined as resources in the form of a globally unique URI or as an anonymous resource. In order to be able to manage different graphs within a database, these are stored as quads, whereby a quad extends each triple by a reference to the associated graph. Building on RDF, a vocabulary has been developed with RDF Schema to formalise weak ontologies and furthermore to describe fully decidable ontologies with the Web Ontology Language.
Algorithms
Important algorithms for querying nodes and edges are:
- Breadth-first search, depth-first search
- Breadth-first search (BFS) is a method for traversing the nodes of a graph. In contrast to depth-first search (DFS), all nodes that can be reached directly from the initial node are traversed first. Only then are subsequent nodes traversed.
- Shortest path
- Path between two different nodes of a graph, which has minimum length with respect to an edge weight function.
- Eigenvector
- In linear algebra, a vector different from the zero vector, whose direction is not changed by the mapping. An eigenvector is therefore only scaled and the scaling factor is called the eigenvalue of the mapping.
Query languages
- Blueprints
- a Java API for property graphs that can be used together with various graph databases.
- Cypher
- a query language developed by Neo4j.
- GraphQL
- an SQL-like query language
- Gremlin
- an open source graph programming language that can be used with various graph databases (Neo4j, OrientDB).
- SPARQL
- query language specified by the W3C for RDF data models.
Distinction from relational databases
When we want to store graphs in relational databases, this is usually only done for specific conditions, e.g. for relationships between people. Adding more types of relationships then usually involves many schema changes.
In graph databases, traversing the links or relationships is very fast because the relationship between nodes doesn’t have to be calculated at query time.
Some of the most popular graph databases are
Selecting the NoSQL database
What all NoSQL databases have in common is that they don’t enforce a particular schema. Unlike strong-schema relational databases, schema changes do not need to be stored along with the source code that accesses those changes. Schema-less databases can tolerate changes in the implied schema, so they do not require downtime to migrate; they are therefore especially popular for systems that need to be available 24/7.
But how do we choose the right NoSQL database from so many? In the following we can only give you some general criteria:
- Key-value databases
- are generally useful for storing sessions, user profiles and settings. However, if relationships between the stored data are to be queried or multiple keys are to be edited simultaneously, we would avoid key-value databases.
- Document databases
- are generally useful for content management systems and e-commerce applications. However, we would avoid using document databases if complex transactions are required or multiple operations or queries are to be made for different aggregate structures.
- Column Family Stores
- are generally useful for content management systems, and high volume writes such as log aggregation. We would avoid using Column Family Stores databases that are in early development and whose query patterns may still change.
- Graph databases
- are well suited for problem areas where we need to connect data such as social networks, geospatial data, routing information as well as recommender system.
Conclusion
The rise of NoSQL databases did not lead to the demise of relational databases. They can coexist well. Often, different data storage technologies are used to store the data to match your structure and required query.
The Cusy vision: DevOps as an API
DevOps: Halfway there
According to studies recently reported by Heise Developer, half of German developers already work according to the DevOps principle. As an advocate of DevOps, one could therefore sit back contentedly and conclude: half the way is already done.
But this is only half the truth. If you look at how DevOps is implemented in many companies, you see that a large proportion of pro-DevOps companies are only halfway there in terms of implementation. While developers in DevOps teams are now taking responsibility for the code in operations as well, conversely not all sysadmins are taking responsibility for the infrastructure in development as well. Often, developer teams still operate their own infrastructure for development, so that the positive effects of the DevOps principle partially evaporate.
The fact that DevOps is a change in culture and not just the use of a few innovative tools is still not widely known. Even many studies that only ask about the use of certain tools like Docker or Puppet paint a false picture of DevOps.
DevOps is not a toolbox, but a redistribution of responsibility in the company. In classic IT departments, responsibility for development/testing and production is distributed as follows.
It is not uncommon for development and operations to even be located in different departments of a company. In the DevOps culture, the vertical separation between development and operations is overturned and a horizontal interface emerges.
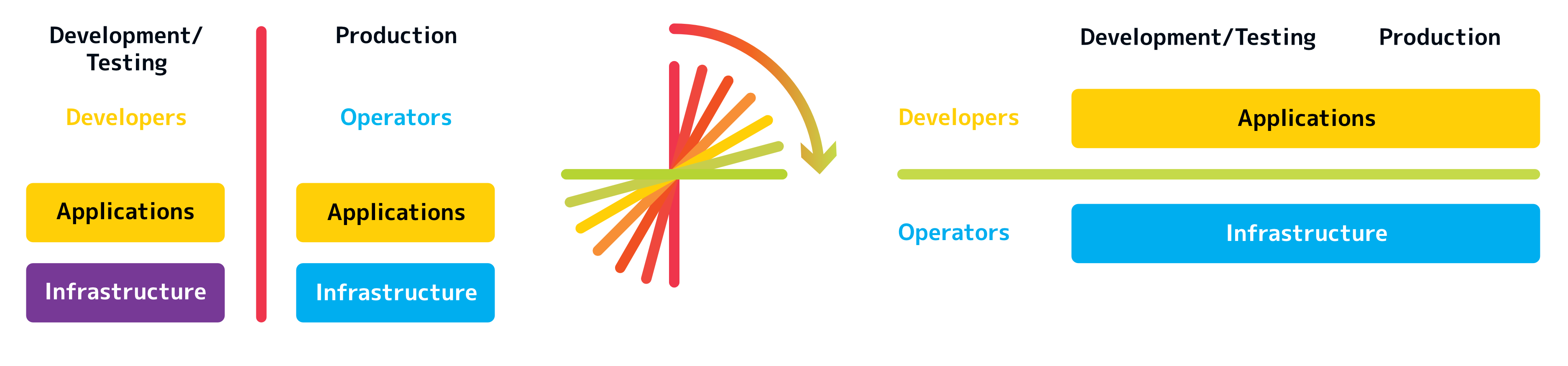
Application developers take responsibility for their application, regardless of whether it is in development or production. Conversely, however, the system administrators also take responsibility for the entire infrastructure from the development environment to the production environment.
So the paradigm shift occurring with DevOps is essentially one that changes the distribution of responsibility, not one that merely provides new tools like Puppet and Chef.
Cusy is the Ops in DevOps
DevOps is the philosophy of unifying Development and Operations at the culture, practice, and tool levels, to achieve accelerated and more frequent deployment of changes to Production.
– Rob England www.itskeptic.org
Cusy facilitates the transition from the classic IT organisation to agile DevOps structures. As a service provider, Cusy takes responsibility for the entire infrastructure: from development to the test environment to the productive system. Cusy is the Ops in DevOps and relieves companies of the task of maintaining their infrastructure themselves. Cusy provides companies not only with the technical infrastructure, but also with the complete development and operating environment, including all the necessary tools.
Thanks to Cusy, application developers can already concentrate fully on their development. They don’t have to worry about the maintenance and care of the necessary development tools such as project management, document management and version management.
Furthermore, the Cusy platform also provides tools for testing and production such as Continuous Integration and log management & analysis.
Finally, Cusy also provides tools for marketing and support such as web analytics and helpdesk.
In addition to all the necessary tools, Cusy also provides VMs for running applications that allow easy Continuous Delivery with GitLab. For this, Cusy provides an API for creating, modifying and deleting VMs. With this, the vision of Cusy has become reality: DevOps as an API.
Springer Nature: Lemma management
The lemma management system is used to manage the contents of the following encyclopaedias:
- Kindlers Literatur Lexikon
- Enzyklopädie der Neuzeit
- Der Neue Pauly
A distinction is made between the following article types:
- Lemma/Sublemma
- Author/co-author
- Volume
- Subject
Technical debts
We usually develop the functionality requested by our customers in short cycles. Most of the time, we clean up our code even after several cycles when the requirements hardly change. Sometimes, however, code that has been developed quickly must also be put into production. Technical debt is a wonderful metaphor in this regard, introduced by Ward Cunningham to think about such problems. Similar to financial debt, technical debt can be used to bridge difficulties. And similar to financial debt, technical debt requires interest to be paid, namely in the form of extra effort to develop the software further.
Unlike financial debt, however, technical debt is very difficult to quantify. While we know that it hinders a team’s productivity in developing the software further, we lack the calculation basis on which to quantify this debt.
To describe technical debt, a distinction is usually made between deliberate and inadvertent technical debt, and between prudent or reckless debt. This results in the following quadrant:
| inadvertent | deliberate | |
| prudent | «Now we know how we should do it!» sollten!»* | «We have to deliver now and deal with the consequences » |
| reckless | «WWhat is software design?» | «We don’t have time Rfor software design!» |
Read more
- Ward Cunningham: Technical Dept
- Ward Cunningham: Complexity As Debt
Rust for cryptography
The programming language Rust [1] is becoming more and more popular and is increasingly used for cryptography. In Rust’s favour is the fact that the language promises very secure memory management, making errors such as buffer overflows and use-after-free less likely. Considering one of the best-known TLS vulnerabilities, the OpenSSL Heartbleed bug [2], which violates memory security, this development is not surprising.
For example, a new TLS backend with Rustls [3] was recently announced for the curl library [4]. Hyper [5], an HTTP library written in Rust, is also to be made available as a backend for curl [6].
The Internet Security Research Group (ISRG) [7] also announced that they will support a Rust-based TLS module for the Apache web server [8]. This is funded as part of Google’s and the ISRG’s efforts to move ports of critical open source software into memory-safe languages [9].
The move of the cryptography package from Python, however, led to heated discussions in the community, as especially some older platforms would no longer be supported without the Rust compiler [10]. The cryptography [#]_project has already started to reimplement parts of its ASN1 parsing code in Rust, [11] [12] as ASN1 parsers often had memory security vulnerabilities in the past.
| [1] | Rust |
| [2] | The Heartbleed Bug |
| [3] | Rustls |
| [4] | curl supports rustls |
| [5] | Hyper |
| [6] | Rust in curl with hyper |
| [7] | Internet Security Research Group |
| [8] | A Memory Safe TLS Module for the Apache HTTP Server |
| [9] | Google Security Blog: Mitigating Memory Safety Issues in Open Source Software |
| [10] | Dependency on rust removes support for a number of platforms #5771 |
| [11] | github.com/pyca/cryptography |
| [12] | Port a tiny tiny bit of the ASN.1 parsing to Rust |
| [13] | Rust in pyca/cryptography |
«Trust is the new oil» in iX 03/2021
This is the central question of this article [1].
No growth without trust
In their European Data Market Monitoring Tool Report [2], the International Data Corporation (IDC) looked at the impact of a climate of trust on the European data economy. They map three different scenarios, whereby they see the most significant factor as the political framework conditions, more precisely data protection and privacy, the common digital market and openness, standardisation and interoperability of data. They expect the greatest growth with a globally applicable GDPR. So it becomes clear: it is not data that is the oil of the digital age, no, it is trust.
Incisive – the Corona Warning App
When, with the corona pandemic, the German government and the Robert Koch Institute (RKI) decided to introduce a contact tracing app, data protection moved into the consciousness of the general population: many feared being stigmatised as COVID-19 patients if this information was passed on to government agencies. Widespread public mistrust of the Corona warning app would have prevent the success. After all, in order to effectively break chains of infection, as many people as possible must use the tracing app. So a completely new question arose: How can we design the software so that enough people trust the app and use it every day?
In April, the Chaos Computer Club published ten touchstones for the assessment of contact tracing apps [3]. For the CCC, the social requirements include purpose limitation, voluntariness and non-discrimination, the protection of privacy as well as transparency and auditability. The technical requirements are the absence of a central entity that must be trusted, data economy, anonymity, no linking with personal data, movement and contact profiles, and confidentiality of communication. The federal government and the RKI did the only right thing: they listened to the advice of the data protectionists and decided – contrary to the original planning – in favour of such a decentralised and anonymous procedure. As expected, trust in the Corona warning app ends at the limits of the operating systems. Whoever controls the technical infrastructure has the power. And it still seems questionable whether and how European data protection standards can ever be enforced against US corporations.
Transparency and openness
In order to be able to judge in an informed way whether a programme fulfils its purpose and has no hidden functions, the source code must be publicly accessible. To ensure full transparency, not only the source code of the programme must be publicly accessible, but also all libraries, protocols and interfaces that a programme uses. The entire software architecture should be based on the open source model for this purpose.
Privacy by design, decentralisation and data sovereignty
If the first two requirements are met, the public can decide whether a software system offers privacy by design or not. Trustworthy software must protect the privacy of users from the outset.
No more blind trust
For decades, users have blindly trusted software manufacturers and service providers. This is different today:
«Software must earn our trust. The future therefore belongs to transparent open source development models that guarantee privacy by design and comprehensive data protection.»
– Veit Schiele, founder and CEO of the Cusy GmbH
| [1] | iX 03/2021: Vertrauen ist das neue Öl – Consent Management in der Softwareentwicklung |
| [2] | IDC: How the power of data will drive EU economy. The European Data MarketMonitoring Tool Report |
| [3] | CCC: 10 Prüfsteine für die Beurteilung von „Contact Tracing“-Apps |
GitLab as quality management system for ISO 13485
Note
The information provided on this website is for informational purposes only. This information is not legal advice. It’s not comprehensive and does not in itself guarantee compliance with ISO 13485. To achieve ISO 13485 compliance, we recommend consulting with specialists.
Create and manage documentation
The GitLab Wiki can be used as a documentation system. Wiki pages can be created and managed via a user-friendly web interface or Git for advanced users. A complete history is guaranteed via version management with Git.
Define and enforce processes
GitLab provides several tools for enforcing processes, standards, reviews and approvals:
- Permissions for merge requests can be used to enforce review of changes before merging.
- Protected development branches can be used to define rules for creating, moving and deleting.
- Requirements management can be enabled in a structured way using issues, labels and relations, with processes enforced and reviewed in a traceable way.
Software validation according to ISO 13485
For the validation of QM software, procedures for the evaluation have to be created. GitLab facilitates this via templates within you can upload forms and other files, create task lists and much more. All actions, including changing the description or commenting, are logged.
Task lists and Kanban boards provide an easy way to organise validation.
IEC 62304 compliance with GitLab
Note
The information provided on this website is for informational purposes only. This information is not legal advice. It’s not comprehensive and does not in itself guarantee IEC 62304 compliance. To achieve IEC 62304 compliance, we recommend consulting with specialists.
Process control
Software development plans and processes can be created, managed and referenced using the GitLab Wiki. It can be used as a comprehensive documentation system to seamlessly reference and integrate your plans and processes throughout the software development lifecycle.
Requirements management
Templates can be created for system, development and customer requirements and easily incorporated into the development process. Task lists and Kanban boards provide both developers and reviewers with easy ways to plan and track tasks.
To enforce requirements and coding standards, you can use Merge Reuqests, an approval process that only allows authorised reviewers to merge the changes made. Using protected branches, you can set detailed permissions on who can make changes and where.
GitLab configured as a service desk allows interaction with customers and external stakeholders to get feedback from them and interact with them.
Traceability
Traceability can be maintained through labels and relations between issues throughout the software development lifecycle. Labels not only allow tasks and merge requests to be facilitated, but notification can also be ensured by subscribing to individual labels.
With the activity log, it remains traceable when which changes were made and by whom.
Risk management
Every code change can be automatically checked for security vulnerabilities with static program analysis. After a scan, a report is generated directly at the merge request, ensuring traceability.
Once risks have been identified, efforts to address them can be planned and documented with issues.
GitLab Compliance Features
- SSH keys
- Minimum SSH key requirements can be set at the instance level.
- Fine-grained user roles and flexible permissions
Authorisations can be managed via five different roles. Assignments can be made differently not only for the instance, but also for groups and projects. The following table gives an overview of the essential authorisations:
Action Guest Reporter Developer Maintainer Owner comment ✓ ✓ ✓ ✓ ✓ View code ✓ ✓ ✓ ✓ ✓ View GitLab pages ✓ ✓ ✓ ✓ ✓ View wiki pages ✓ ✓ ✓ ✓ ✓ View job list ✓ ✓ ✓ ✓ ✓ View job protocol ✓ ✓ ✓ ✓ ✓ Create issues ✓ ✓ ✓ ✓ ✓ Assign issues ✓ ✓ ✓ ✓ Assign reviewer ✓ ✓ ✓ ✓ Assign labels ✓ ✓ ✓ ✓ Manage labels ✓ ✓ ✓ ✓ Lock issues ✓ ✓ ✓ ✓ Manage issue tracker ✓ ✓ ✓ ✓ View commit status ✓ ✓ ✓ ✓ View container registry ✓ ✓ ✓ ✓ View environments ✓ ✓ ✓ ✓ View list of merge requests ✓ ✓ ✓ ✓ Create merge request ✓ ✓ ✓ ✓ View CI/CD analysis ✓ ✓ ✓ ✓ Manage token ✓ ✓ Change security level ✓ Move project ✓ Rename project ✓ Delete Project ✓ Archive project ✓ Delete issues ✓ Delete pipelines ✓ Deactivate notification mails ✓ - Force acceptance of terms of use
- Acceptance of the terms of use can be enforced instance-wide.
Compliance management with Gitlab
In detail, GitLab supports
- managing rules and policies
- automating compliance workflows
- audit management that logs activities, identifies incidents and proves compliance with rules
- security management that checks the security of the source code to track and manage vulnerabilities (→ DevSecOps).
Policy management
Rules and policies to be followed can be defined, both internal company policies and policies based on legal or regulatory frameworks such as GDPR, SOC2, PCI-DSS, SOX, HIPAA, ISO, COBIT, FedRAMP, etc. GitLab provides the following functions for this purpose:
- Fine-grained user roles and permissions
- GitLab supports five different roles with different permissions
- Compliance settings
- Different compliance policies can be set for different projects.
- Inventory
- All actions are inventoried.
Automate compliance workflows
Once the policies and rules are established, the processes can be automated, e.g. through
- Project templates
- Project templates with specific audit protocols and audit trails, such as HIPAA, can be created.
- Project label
- Depending on the policy, different labels can be predefined for projects and tasks.
Audit management
Compliance audits require the traceability of various events such as user actions, changes to authorisations or approvals.
| [1] | ISO 19600:2014 Compliance management systems — Guidelines |
Software reviews – does high-quality software justify its cost?
What are the benefits of software reviews?
Software reviews lead to significantly fewer errors. According to a study of 12 thousand projects by Capers Jones [1], these are reduced by
- in requirements reviews by 20–50 percent
- in top-level design reviews by 30–60 percent
- in detailed functional design reviews by 30–65 percent
- for detailed logical design reviews by 35–75percent
The study concludes:
Poor code quality is cheaper until the end of the code phase; after that, high quality is cheaper.
The study still assumes a classic waterfall model from requirements to software architecture, first to code, then to tests and operation. In agile software development, however, this process is repeated in many cycles, so that we spend most of our time developing software by changing or adding to the existing code base. Therefore, we need to understand not only the change requirements but also the existing code. Better code quality makes it easier for us to understand what our application does and how the changes make sense. If code is well divided into separate modules, I can get an overview much faster than with a large monolithic code base. Further, if the code is clearly named, I can more quickly understand what different parts of the code do without having to go into detail. The faster I understand the code and can implement the desired change, the less time I need to implement it. To make matters worse, the likelihood that I will make a mistake increases. More time is lost in finding and fixing such errors. This additional time is usually accounted for as technical debt.
Conversely, I may be able to find a quick way to provide a desired function, but one that goes beyond the existing module boundaries. Such a quick and dirty implementation, however, makes further development difficult in the weeks and months to come. Even in agile software development without adequate code quality, progress can only be fast at the beginning, the longer there is no review, the tougher the further development will be. In many discussions with experienced colleagues, the assessment was that regular reviews and refactorings lead to higher productivity after just a few weeks.
Which types of review solve which problems?
There are different ways to conduct a review. These depend on the time and the goals of the review.
The IEEE 1028 standard [2] defines the following five types of review:
- Walkthroughs
- With this static analysis technique we develop scenarios and do test runs, e.g. to find anomalies in the requirements and alternative implementation options. They help us to better understand the problem, but do not necessarily lead to a decision.
- Technical reviews
- We carry out these technical reviews, e.g. to evaluate alternative software architectures in discussions, to find errors or to solve technical problems and come to a (consensus) decision.
- Inspections
- We use this formal review technique, for example, to quickly find contradictions in the requirements, incorrect module assignments, similar functions, etc. and to be able to eliminate these as early as possible. We often carry out such inspections during pair programming, which also provides less experienced developers with quick and practical training.
- Audits
- Often, before a customer’s software is put into operation, we conduct an evaluation of their software product with regard to criteria such as walk-through reports, software architecture, code and security analysis as well as test procedures.
- Management reviews
- We use this systematic evaluation of development or procurement processes to obtain an overview of the project’s progress and to compare it with any schedules.
Customer testimonials
«Thank you very much for the good work. We are very happy with the result!»
– Niklas Kohlgraf, Projektmanagement, pooliestudios GmbH
Get in touch
I would be pleased to answer your questions and create a suitable offer for our software reviews.
We will also be happy to call you!
| [1] | Capers Jones: Software Quality in 2002: A Survey of the State of the Art |
| [2] | IEEE Standard for Software Reviews and Audits 1028–2008 |
Atlassian discontinues the server product range
Atlassian announced in mid-October 2020 that it would completely discontinue its server product line for the products Jira, Confluence, Bitbucket and Bamboo on 2 February 2021. Existing server licences will still be able to be used until 2 February 2024, although it is doubtful that Atlassian will actually continue to provide extensive support until 2 February 2024.
The product series will be phased out in stages:
- 2 February 2021: New server licences will no longer be sold and price increases will come into effect.
- 2 February 2022: Upgrades and downgrades will no longer be possible
- 2 February 2023: App purchases for existing server licences will no longer be possible
- 2 February 2024: End of support
While Atlassian recommends migrating to the cloud, many of our customers refuse to do so due to business requirements or data protection reasons. We work with our customers to analyse the requirements of their existing Jira, Confluence, Bitbucket and Bamboo servers and then develop suitable migration plans, e.g. to GitLab.
Get in touch
Even if you are not yet a customer of ours, I will be happy to answer your questions and create a customised offer for the migration of your Atlassian servers.
I will also be happy to call you!
Migration from Jenkins to GitLab CI/CD
Our experience is that migrations are often postponed for a very long time because they do not promise any immediate advantage. However, when the tools used are getting on in years and no longer really fit the new requirements, technical debts accumulate that also jeopardise further development.
Advantages
The advantages of GitLab CI/CD over Jenkins are:
- Seamless integration
- GitLab provides a complete DevOps workflow that seamlessly integrates with the GitLab ecosystem.
- Better visibility
- Better integration also leads to greater visibility across pipelines and projects, allowing teams to stay focused.
- Lower cost of ownership
- Jenkins requires significant effort in maintenance and configuration. GitLab, on the other hand, provides code review and CI/CD in a single application.
Getting started
Migrating from Jenkins to GitLab doesn’t have to be scary though. Many projects have already been switched from Jenkins to GitLab CI/CD, and there are quite a few tools available to ease the transition, such as:
Run Jenkins files in GitLab CI/CD.
A short-term solution that teams can use when migrating from Jenkins to GitLab CI/CD is to use Docker to run a Jenkins file in GitLab CI/CD while gradually updating the syntax. While this does not fix the external dependencies, it already provides better integration with the GitLab project.
Use Auto DevOps
It may be possible to use Auto DevOps to build, test and deploy your applications without requiring any special configuration. One of the more involved tasks of Jenkins migration can be converting pipelines from Groovy to YAML; however, Auto DevOps provides predefined CI/CD configurations that create a suitable default pipeline in many cases. Auto DevOps offers other features such as security, performance and code quality testing. Finally, you can easily change the templates if you need further customisation.
Best Practices
Start small!
The Getting Started steps above allow you to make incremental changes. This way you can make continuous progress in your migration project.
Use the tools effectively!
Docker and Auto DevOps provide you with tools that simplify the transition.
Communicate transparently and clearly!
Keep the team informed about the migration process and share the progress of the project. Also aim for clear job names and design your configuration in such a way that it gives the best possible overview. If necessary, write comments for variables and code that is difficult to understand.
Get in touch
I will be happy to answer your questions and create a customised offer for the migration of your Jenkins pipeline to GitLab CI/CD.
I will also be happy to call you!
Cheat sheets for our Python seminars
For our Python training for analysts, scientists and engineers we have created cheat sheets that allow the course participants to quickly reuse what they have learned:
- Python Cheat Sheet


python-for-beginners-cheat-sheet.pdf, PDF, 70.4 KB


- Pandas Cheat Sheet


pandas-cheat-sheet.pdf, PDF, 52 KB


- Git Cheat Sheet


git-cheatsheet-web.pdf, PDF, 437 KB


And if you have any further questions about our training courses, please give us a call on +49 30 22430082 or send us an email to training@cusy.io.
Microsoft alternatives – migration to open source technologies
We are developing a migration strategy from Microsoft 365 to open source technologies for a large German research company. On the one hand, it’s a question of regaining cyber souvereignty and, on the other hand, of meeting increased security requirements. This is to be achieved by using free and open source software (FLOSS). Overall, the project is similar to the Microsoft Alternatives Project (MAlt) at CERN and the Project Phoenix of Dataport.
The principles of the project are:
- The same service should be offered to all employees
- Vendor lock-ins should be avoided in order to reduce the risk of dependency
- Most of the data should be owned by the research company
We evaluate alternative solutions for many services, implement prototypes and pilot projects.
| Product group | Service | Product to evaluate | Status |
|---|---|---|---|
| Identity and access management | LDAP | OpenLDAP | 🏭 Production |
| Personal Information Management | Zimbra | 🚦 Evaluation | |
| Calendar | Zimbra | 🚦 Evaluation | |
| Contacts | Zimbra | 🚦 Evaluation | |
| Collaboration | File sharing | NextCloud | 🏭 Production |
| Office integration | NextCloud | 🚦 Evaluation | |
| Direct mails/chat | Mattermost | 🏭 Production | |
| Video conferences | Jitsi Meet | 🏭 Production | |
| Search | Search engine | OpenSearch | 🚦 Evaluation |
| Frontend/ Visualisierung | OpenSearch Dashboards | 🚦 Evaluation | |
| Authentication/ Access control | Open Distro Security | 🚦 Evaluation | |
| k-nearest neighbors | Open Distro KNN | 🚦 Evaluation | |
| Project management | Issues/Milestones | GitLab | 🚦 Evaluation |
| Time tracking | gitlabtime | 🚦 Evaluation | |
| Documentation | GitLab Wiki | 🚦 Evaluation | |
| Research software [1], [2] | Package manager | Spack | 🏭 Production |
| IDE | JupyterHub | 🏭 Production | |
| Development environments | Jupyter Kernels | 🏭 Production | |
| Software versioning | Git | 🏭 Production | |
| Data versioning | DVC | 🏭 Production | |
| Gathering and storing data | Intake | 🛫 Pilot | |
| Spreadsheet | ipysheet | 🏭 Production | |
| Geospatial data | PostGIS | 🏭 Production | |
| Map creation | OpenStreetMap | 🏭 Production | |
| DevOps | GitLab CI/CD Pipeline | 🛫 Pilot | |
| Documentation | Sphinx | 🏭 Production |
Hosting strategy
There are essentially three different hosting variants within the research company:
- Society-wide infrastructure
- Infrastructure, which is used by most of the research projects and administrations across the institutes, is to be provided by the research company’s central IT.
- Institute-wide infrastructure
- Infrastructure that is required for the special research areas of one institute or that needs IT support on site should be provided by the IT of the respective institute.
- Operational and geo-redundancy
- These are mainly produced through institute cooperation or through cooperation between individual institutes and the IT of the research society. In terms of technology, floating IPs and the Virtual Router Redundancy Protocol (VRRP) are used for this, with decisions being made on the basis of BGP announcements.
| [1] | There is extensive German documentation for the infrastructure on which the research software is developed, which is published under the BSD 3 Clause license: |
| [2] | The planned uniform API represents a significant simplification here; see also Announcing the Consortium for Python Data API Standards. |
Data protection in times of Covid-19
Companies and organizations have data that they do not want to make available to others. They also have a special responsibility for their customers, partners and employees. Not being sovereign of this data means not only a loss of trust, but usually also commercial losses.
Show your customers, partners and employees that data protection is important to you and that you take responsibility to protect their privacy. Show that you have implemented the rules of the European General Data Protection Regulation (GDPR) from May 2018.
Therefore, do without Google services and use alternatives. Google makes money from the data you provide Google:
With your permission you give us more information about you, about your friends, and we can improve the quality of our searches. We don’t need you to type at all. We know where you are. We know where you’ve been. We can more or less know what you’re thinking about. [1]
This statement by the Google CEO, Eric Schmidt, is more relevant than ever. It can get scary when you think that a company knows more or less what you think about. The group only reveals part of this information if you still have a Google account – saved graphs and other evaluations will remain hidden from you.
In the following we would like to introduce you to some privacy-friendly alternatives to Google services:
… for your office work
- Jitsi instead of Google Hangout, Zoom or Microsoft Teams
- Mattermost instead of Slack
- Nextcloud and OnlyOffice instead of Google Docs, Google Sheets, Google Slides, Google Calendar and Google Drive
… for your website
- Elasticsearch instead of Google Search
- Matomo instead of Google Analytics
- TextCaptcha or Securimage instead of Google reCAPTCHA
- Own OpenStreetMap server and Leaflet instead of Google Maps on websites
- Deliver fonts yourself with Make Google Fonts local and Google Webfonts Helper instead of Google Fonts
For further reading
- Telearbeit und Mobiles Arbeiten
- Information from the Federal Commissioner for Data Protection and Freedom of information (BfDI), January 2019
- Top Tips for Cybersecurity when Working Remotely
- Article by the European Union Agency for Cybersecurity (ENISA), March 2020
- Home-Office? – Aber sicher!
- Information from the Federal Office for Information Security (BSI), March 2020
| [1] | Google’s CEO: ‹The Laws Are Written by Lobbyists›, 2010. |
Beuth University: Prototype for a medication app
For the Beuth University, we develop a prototype for a medication app.
The app is intended to improve the safety of the medication and in particular in the monitoring of ingestion rhythm and the knowledge of side effects and influences.
Not only the patients themselves should be able to use this app, but also relatives and caregivers.
In fact, there are already many apps that promise to meet the requirements. However, with more detailed research, they have significant shortcomings.
Professional quality
The professional quality of other apps is rarely discernible and, if the few reviews are taken as a basis, is usually very low. This is all the more problematic when apps promise to point out interactions and double prescriptions for medications with similar effects. For customers who rely on the fact that their app will warn them of dangers, for example with their self-medication requests, are likely to be at serious risk.
User groups
The apps also very rarely provide information about their user groups, neither about
- Suitability for specific diseases/conditions
- Suitability for gender, special age groups (or areas) etc.
- Suitability for certain health professions and settings: clinical, outpatient, at home, …
- Suitability for physiological and physical impairments, also not the support for TalkBack for Android and VoiceOver for iPhone.
- Support for country-specific drugs and pack sizes
Privacy
The handling of user data is usually poor. The data protection declarations usually leave customers unclear as to what happens to their information. This is all the more problematic since over 80% of the apps transfer data to infrastructure providers such as Google, Facebook etc. Not even the encrypted transmission of user data was always guaranteed, especially not when data was transmitted by email. The few independent test procedures are unlikely to contribute to clarification, since they mostly rely on self-assessment.
Are Jupyter notebooks ready for production?
In recent years, there has been a rapid increase in the use of Jupyter notebooks, s.a. Octoverse: Growth of Jupyter notebooks, 2016-2019. This is a Mathematica- inspired application that combines text, visualisation, and code in one document. Jupyter notebooks are widely used by our customers for prototyping, research analysis and machine learning. However, we have also seen that the growing popularity has also helped Jupyter notebooks be used in other areas of data analysis, and additional tools have been used to run extensive calculations with them.
However, Jupyter notebooks tend to be inappropriate for creating scalable, maintainable, and long-lasting production code. Although notebooks can be meaningfully versioned with a few tricks, automated tests can also run, but in complex projects, mixing code, comments and tests becomes an obstacle: Jupyter notebooks can not be sufficiently modularized. Although notebooks can be imported as modules, these options are extremely limited: the notebooks must first be fully loaded into memory and a new module must be created before each cell can run in it.
As a result, it came to the first notebook war, which was essentially a conflict between data scientists and software engineers.
How To Bridge The Gap?
Notebooks are rapidly gaining popularity among data scientists and becoming the de facto standard for rapid prototyping and exploratory analysis. Above all, however, Netflix has created an extensive ecosystem of additional tools and services, such as Genie and Metacat. These tools simplify complexity and support a broader audience of analysts, scientists and especially computer scientists. In general, each of these roles depends on different tools and languages. Superficially, the workflows seem different, if not complementary. However, at a more abstract level, these workflows have several overlapping tasks:
data exploration occurs early in a project
This may include displaying sample data, statistical profiling, and data visualization
- Data preparation
iterative task
may include cleanup, standardising, transforming, denormalising, and aggregating data
- Data validation
recurring task
may include displaying sample data, performing statistical profiling and aggregated analysis queries, and visualising data
- Product creation
occurs late in a project
This may include providing code for production, training models, and scheduling workflows
A JupyterHub can already do a good job here to make these tasks as simple and manageable as possible. It is scalable and significantly reduces the number of tools.
To understand why Jupyter notebooks are so compelling for us, we highlight their core functionalities:
- A messaging protocol for checking and executing language-independent code
- An editable file format for writing and capturing code, code output, and markdown notes
- A web-based user interface for interactive writing and code execution and data visualisation
Use Cases
Of our many applications, notebooks are today most commonly used for data access, parameterization, and workflow planning.
Data access
First we introduced notebooks to support data science workflows. As acceptance grew, we saw an opportunity to leverage the versatility and architecture of Jupyter notebooks for general data access. Mid-2018, we started to expand our notebooks from a niche product to a universal data platform.
From the user’s point of view, notebooks provide a convenient interface for iteratively executing code, searching and visualizing data – all on a single development platform. Because of this combination of versatility, performance, and ease of use, we have seen rapid adoption across many user groups of the platform.
Parameterization
Along with increasing acceptance, we have introduced additional features for other use cases. From this work notebooks became simply paramatable. This provided our users with a simple mechanism to define notebooks as reusable templates.
Workflow planning
As a further area of notebook applications, we have discovered the planning of workflows. They have the following advantages, among others:
- On the one hand, notebooks allow interactive work and rapid prototyping and on the other hand they can be put into production almost without any problems. For this the notebooks are modularized and marked as trustworthy.
- Another advantage of notebooks are the different kernels, so that users can choose the right execution environment.
- In addition, errors in notebooks are easier to understand because they are assigned to specific cells and the outputs can be stored.
Logging
In order to be able to use notebooks not only for rapid prototyping but also for long-term productivity, certain process events must be logged so that, for example, errors can be diagnosed more easily and the entire process can be monitored. IPython Notebboks can use the logging module of the standard Python library or loguru, see also Jupyter-Tutorial: Logging.
Testing
There have been a number of approaches to automate the testing of notebooks, such as nbval, but with ipytest writing notebook tests became much easier, see also Jupyter Tutorial: ipytest.
Summary
Over the last few years, we have been promoting close collaboration between Software Engineers and data scientists to achieve scalable, maintainable and production-ready code. Together, we have found solutions that can provide production-ready models for machine learning projects as well.
elena international: Web-based planning tool for microgrids
elena international is a startup company that provides customised solutions for various stages of power system planning.
First we realise a walking skeleton of a web-based planning tool for microgrids.
The chosen software architecture allows elena the further development of its Julia libraries. In the Web tool the adoption of new features takes place in IPython notebooks with PyJulia. These notebooks can also be used to define the voila-vuetify widgets for interacting with users. Finally, with Voilà, these notebooks are converted into an interactive dashboard:

To harden the notebooks for production, on the one hand we write tests for each method, which run regularly with GitLab CI/CD, and on the other hand we activate logging for fault diagnosis and monitoring.
So we are not only answering the question Are Jupyter notebooks ready for production?, we also extend the possibilities of notebooks: they serve an editor system, in which not only texts can be written and media added, but also the presentation logic of scientific calculations and interactive widgets can be defined.