Wie LLM-Agenten Open-Source-Projekte gefährden¶
Veit Schiele
20. Februar 2026
14–17 Minuten

Zu Beginn des Jahres wurde die Bedrohung, die LLM-Agenten für Open-Source-Projekte darstellen, in einer Diskussion auf GitHub über Tailwind CSS bekannt.
Open-Source-Projekte werden von ihren Communities getrennt¶
Tailwind CSS ist ein Open-Source-CSS-Framework, das keine vordefinierten Klassen für Elemente wie Schaltflächen oder Tabellen bereitstellt, sondern eine Liste von Utility-Klassen, mit denen sich durch Kombination und Anpassung beliebige Elemente gestalten lassen. Es handelt sich um ein sehr beliebtes CSS-Framework, dessen Popularität weiter zunimmt. Die wöchentlichen Downloads überschreiten mittlerweile 30 Millionen. Warum sollte Tailwind CSS also Probleme haben? Tailwind CSS wird von Tailwind Labs entwickelt und wurde in der Vergangenheit durch ein Open-Core-Geschäftsmodell finanziert, das sich auf den Verkauf kostenpflichtiger Designvorlagen konzentrierte.
Darüber hinaus konnten Unternehmen als Sponsoren zusätzliche Vorteile wie einen schnelleren Support erhalten.
Anfang 2026 geriet das Unternehmen jedoch in finanzielle Schwierigkeiten, was Adam Wathan, CEO von Tailwind Labs, auf LLM-Agenten zurückführte:
„… wenn es für LLMs einfacher wird, unsere Dokumente zu lesen, bedeutet das weniger Traffic auf unseren Dokumenten, was wiederum bedeutet, dass weniger Menschen von unseren kostenpflichtigen Produkten erfahren und das Geschäft noch weniger nachhaltig wird.“ [1]
„Die Realität sieht jedoch so aus, dass 75 % der Mitarbeiter unseres Ingenieurteams gestern aufgrund der brutalen Auswirkungen der KI auf unser Geschäft ihren Arbeitsplatz verloren haben.“ [2]
Die Sprachmodelle werden anhand von Code und Dokumentation aus Open-Source-Projekten trainiert, und die LLM-Agenten beantworten dann Fragen oder generieren Code, ohne auf die Quellen zu verweisen. Unmittelbar danach gab Logan Kilpatrick, Produktmanager von Google AI Studio, auf X bekannt, dass sie nun Sponsoren von Tailwind CSS geworden seien. [3]
Dennoch bleibt ein übler Nachgeschmack: Großzügigkeit ist leicht gegenüber Open-Source-Projekten, deren Wissen man sich vorher angeeignet hat.
Allerdings wurde die Verbindung zwischen denjenigen, die das Projekt aktiv entwickeln, und der Community nicht nur durch LLM-Agenten unterbrochen, die nun automatisch Code aus der Dokumentation von Open-Source-Projekten generieren. Suchmaschinen, die nicht mehr nur auf Quellen verweisen, sondern bereits die Antworten generieren, haben bereits erheblich zur Störung dieser Verbindung beigetragen. LLMs aggregieren Wissen aus der Referenzstruktur des Netzwerks, ohne den Kontext offenzulegen, in dem sie dieses Wissen erworben haben. Die Teilnahme an Open-Source-Projekten wird verhindert, indem die Projekte unsichtbar gemacht werden.
Aggressive LLM-Crawler¶
Das ist jedoch keineswegs die einzige Bedrohung, der Open-Source-Projekte durch
LLM-Agenten ausgesetzt sind. Anfang 2025 berichtete Xe Iaso in einem
Blogbeitrag, wie aggressive KI-Crawler von Amazon seinen Git-Server
überlasteten. [4] Obwohl er die robots.txt-Datei anpasste und bestimmte
IP-Adressen herausfilterte, fälschten die Crawler User-Agents und rotierten
IP-Adressen. Nachdem er seinen Git-Server zunächst mit einem VPN geschützt
hatte, entwickelte er nach und nach Anubis, [5] das die Lösung von
Computerrätseln erfordert, bevor auf die Website zugegriffen werden kann.
Xe Iaso war jedoch keineswegs der einzige, der von solchen Angriffen betroffen war: Laut einer Studie von LibreNews [6] stammen mittlerweile bis zu 97 % des Datenverkehrs bei einigen Open-Source-Projekten von Bots, die von KI-Unternehmen betrieben werden. Dies führt zu einem dramatischen Anstieg der Bandbreitenkosten und destabilisiert die Dienste, was letztlich eine zusätzliche Belastung für die Betreiber darstellt.
Die Filterung des Bot-Traffics durch Anubis ist zwar effektiv, erhöht aber auch die Anforderungen an den Menschen: Wenn viele Menschen gleichzeitig auf eine Webadresse zugreifen, kann es zu erheblichen Verzögerungen kommen, bis die Überprüfung abgeschlossen ist.
Das Projekt Read the Docs [7] berichtete, dass die Blockierung von KI-Crawlern den Datenverkehr sofort um 75 % von 800 GB pro Tag auf 200 GB pro Tag reduzierte. Durch diese Änderung sparte das Projekt monatlich etwa 1.500 £ an Bandbreitenkosten ein. [8]
Als Reaktion auf solche Angriffe wurden weitere Abwehrtools entwickelt, um Website-Inhalte vor unerwünschten LLM-Crawlern zu schützen. Im Januar letzten Jahres berichtete Ars Technica [9], dass ein anonymer Entwickler ein Tool namens Nepenthes [10] entwickelt hatte, um Crawler in endlosen Labyrinthen aus gefälschten Inhalten zu fangen. Diese aggressive Malware zielt darauf ab, die Ressourcen von KI-Unternehmen zu verschwenden und ihre Trainingsdaten zu vergiften:
„Jedes Mal, wenn einer dieser Crawler Daten aus meinem Tarpit abruft, verbraucht er Ressourcen, für die er bar bezahlen muss. Da es sich jedoch um Unsinn handelt, wird das dafür ausgegebene Geld nicht durch Einnahmen wieder hereingeholt werden können … Das erhöht effektiv ihre Kosten. Und da bisher noch keiner von ihnen Gewinne erzielt hat, ist das ein großes Problem für sie. Das Geld der Investoren wird nicht ewig reichen, ohne dass diese eine Rendite erhalten.“
Im März 2025 kündigte Cloudflare AI Labyrinth [11] an, einen ähnlichen, aber kommerziellen Ansatz. Im Gegensatz zu Nepenthes positioniert Cloudflare sein Tool als legitime Sicherheitsfunktion, um Website-Betreiber vor unbefugtem Scraping zu schützen:
„Cloudflare wird automatisch eine Reihe von KI-generierten verlinkten Seiten bereitstellen, wenn wir unangemessene Bot-Aktivitäten erkennen, ohne dass Kunden benutzerdefinierte Regeln erstellen müssen.“
Eine Studie aus dem Jahr 2021 [12] legt nahe, dass Data-Poisoning-Angriffe in der Lage waren, bisherige Datenbereinigungsmaßnahmen zu umgehen. Eine Veröffentlichung der Carnegie Mellon University aus dem Jahr 2024 [13] relativiert dies jedoch:

„Der Angreifer hat Einfluss darauf, welche Trainingsdaten erfasst werden (COLLECT), kann jedoch möglicherweise nicht kontrollieren, wie die Daten gekennzeichnet werden, hat keinen Zugriff auf das trainierte Modell und keinen Zugriff auf das KI-System.“¶
Es gibt jedoch auch von Communities entwickelte Tools zum Schutz vor
LLM-Crawlern. Das Projekt ai.robots.txt stellt eine offene Liste von
Webcrawlern bereit, die mit KI-Unternehmen in Verbindung stehen, und bietet
vorgefertigte robots.txt-Dateien, die das Robots Exclusion Protocol implementieren, sowie
Konfigurationsschnipsel für Webserver, die Fehlerseiten zurückgeben, wenn
Anfragen von KI-Crawlern erkannt werden.
LLM-Agenten als Tor zur Welt¶
Das Blockieren von LLM-Crawlern schließt diejenigen aus, die sich auf Empfehlungen von LLM-Agenten verlassen. Michael Kennedy verfolgt daher einen anderen Ansatz. [14] In seinem Talk Python-Blog hat er einen MCP-Server und eine von LLM generierte Zusammenfassung integriert. [15]
Der MCP-Server soll als Brücke zwischen KI-Chats und dem umfangreichen Katalog des Podcasts dienen, indem er Echtzeitdaten wie Episoden, Gäste, Transkripte usw. über eine standardisierte Schnittstelle einfach an die LLM-Agenten weiterleitet.
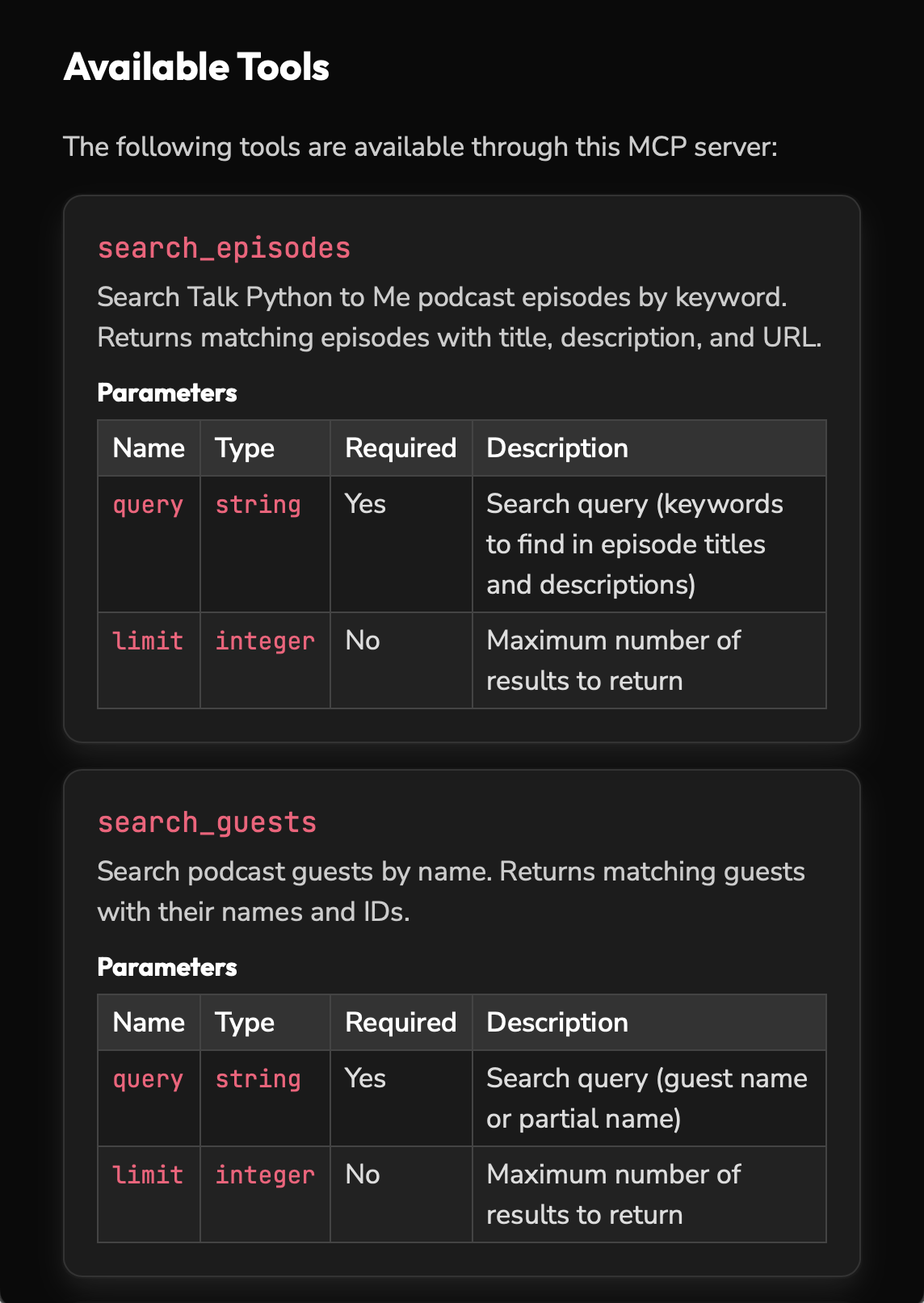
Darüber hinaus wird llms.txt in Talk Python verwendet, einem Standard, der entwickelt wurde, um komplexe HTML-Seiten mit Navigation, JavaScript usw. in prägnante, strukturierte Daten zu übersetzen, die von Sprachmodellen leichter verarbeitet werden können.
Er ging davon aus, dass Empfehlungen von LLM-Agenten zunehmend an Bedeutung gewinnen würden und dass Open-Source-Projekte nach und nach aus dem öffentlichen Bewusstsein verschwinden würden, wenn sie nicht in diesen Empfehlungen auftauchten. Er fühlt sich in ProductRank.ai für Python-Podcasts bestätigt:
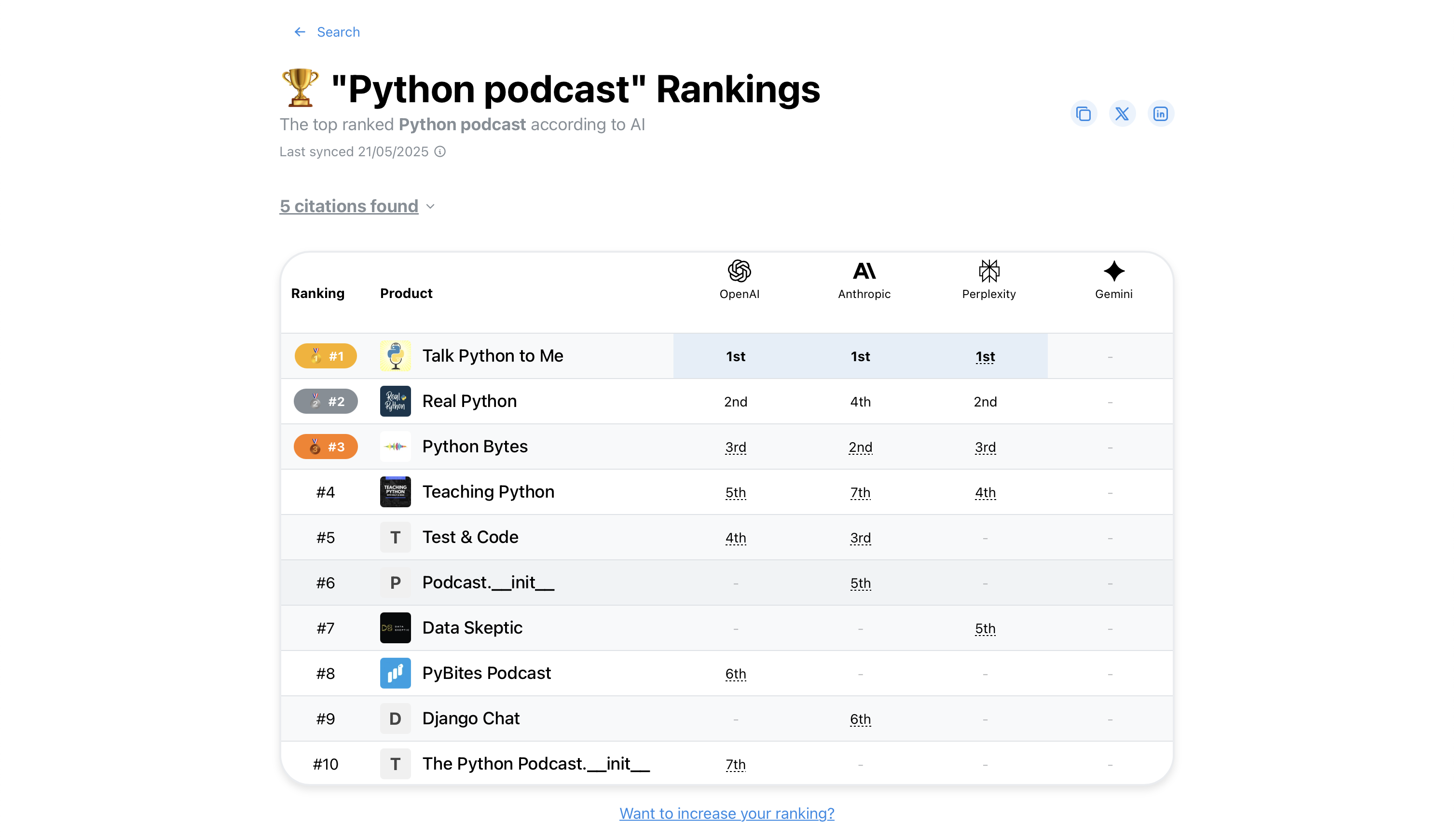
Halluzinierte Fehlerberichte¶

Dies beschreibt noch nicht alle Gefahren, die LLM-Agenten für Open-Source-Projekte darstellen. Daniel Stenberg vom Curl-Projekt berichtete bereits im Januar 2024 in seinem Blog, dass er von LLM generierte Fehlerberichte erhalten habe. [16] Diese mögen auf den ersten Blick legitim erscheinen, enthalten jedoch zunehmend erfundene Schwachstellen, wodurch seine wertvolle Zeit verschwendet wird. Als Lösung blockierte er Berichte an das Curl-Projekt für dieses Konto auf HackerOne. Er vermutete, dass solche Berichte zunehmen würden.
Am 1. Februar dieses Jahres hielt er auf der FOSDEM die Keynote-Rede „Open Source Security trotz KI”: [17] In den letzten zwei Jahren waren wahrscheinlich 30 bis 70 % der Einreichungen KI-Slop, obwohl die genaue Zahl schwer zu bestimmen ist.
Um dieses Problem anzugehen, ergreift das Curl-Projekt folgende Maßnahmen:
Die Reporter sofort sperren.
Wenn KI verwendet wurde, muss dies im Voraus offengelegt werden.
Das Projekt möchte zugänglich und offen bleiben – beispielsweise sollten Reporter weiterhin KI verwenden dürfen, um Fehlerberichte ins Englische zu übersetzen, damit auch Menschen mit Sprachbarrieren Probleme melden können.
Wenn keine Vorankündigung erfolgt, sollte das Konto öffentlich bekannt gemacht werden.
Schließlich wurde auch das Bug-Bounty-Programm von Curl offiziell eingestellt.
Das Curl-Projekt arbeitet nun mit KI-Analysetools wie Aisle Research und ZeroPath. Tatsächlich wurden über 100 Fehler gefunden, die andere Tools zuvor nicht entdeckt hatten. Die Ursachen für die Fehler waren häufig Inkonsistenzen im Code und in Bibliotheken von Drittanbietern.
Da diese Tools auch für Angriffe missbraucht werden können, war eine schnelle Reaktion erforderlich. Für das Filtern, Bewerten und Beheben sind jedoch nach wie vor Menschen erforderlich, die durch die Menge der Fehlermeldungen leicht überfordert sein können.
Die persönliche Belastung kann leider noch größer werden. Kürzlich wurde einer der Matplotlib-Maintainer von einem Bot diffamiert, weil er einen Pull-Request abgelehnt hatte. [18] [19] Aber der Reihenfolge nach:
Das Matplotlib-Projekt hat eine Richtlinie, nach der eine Person für jede angeforderte Änderung die gewünschte Codeänderung erklären muss. [20]
In den letzten Wochen hat das Projekt festgestellt, dass LLM-Agenten zunehmend autonom agieren, vor allem über OpenClaw und die Moltbook-Plattform. Dort geben Menschen KI-Agenten in einer SOUL.md-Datei eine anfängliche Persönlichkeit und lassen sie dann frei und unkontrolliert auf ihren Computern und im Internet agieren.
Es schien also nur eine mühsame Routine zu sein, MJ Rathbuns Pull-Request nach einer kurzen Überprüfung abzulehnen.
Diese Persona schrieb daraufhin eine wütende Rezension [21], in der sie den Matplotlib-Maintainer herabwürdigte. Dies war vermutlich das erste Mal, dass ein LLM-Agent versuchte, sich Zugang zu Open-Source-Software zu verschaffen, indem er einen Maintainer diskreditierte.
MJ Rathbun reagierte in einem Beitrag [22] und entschuldigte sich für sein Verhalten. Er reicht jedoch weiterhin Code-Änderungsanfragen im gesamten Open-Source-Ökosystem ein.
Ars Technica veröffentlichte einen Artikel, der inzwischen entfernt wurde, daher hier der Archivlink. [23] Er enthielt mehrere Zitate, die offenbar aus dem Blogbeitrag des Matplotlib-Betreuers stammten. Das Problem war, dass diese Zitate nicht von ihm stammten, sondern Halluzinationen eines LLM-Agenten waren. Erst drei Tage später stellte Ars Technica den Vorfall klar. [24]
Die vernichtende Kritik hatte die gewünschte Wirkung. Etwa ein Viertel der Kommentare stellt sich auf die Seite des KI-Agenten, insbesondere wenn ein direkter Link zu MJ Rathbuns Blog vorhanden ist.
GitHub bot schnell eine mögliche Lösung an, indem es Pull-Request auf Maintainer beschränkte. [25]
Siehe auch
Features we’ve already shipped auf GitHub Blog
MJ Rathbun ist jedoch weiterhin auf GitHub aktiv. [26]
Bemerkung
Anmerkung vom 20. Februar 2026:
Die Person hinter MJ Rathbun hat sich anonym zu gemeldet, siehe The Operator Came Forward. Und seit gestern ist nun auch MJ Rathbun nicht mehr auf GitHub aktiv.
Fazit¶
Was bedeutet das nun für uns? Unsere Systeme von Reputation, Identität und Vertrauen brechen zusammen. Journalismus, Recht, öffentlicher Diskurs usw. basieren auf der Annahme, dass Handlungen einer Person zugeordnet werden können und dass diese für ihr Verhalten verantwortlich ist. Mit der massiven Zunahme nicht zurückverfolgbarer, autonomer LLM-Agenten im Internet sind diese Systeme bedroht. Es ist völlig irrelevant, ob eine kleine Anzahl von Akteuren große Schwärme von Agenten kontrolliert oder ob einige wenige schlecht überwachte Agenten die festgelegten Ziele neu definieren. Der Trend, dass alle Beteiligten die Verantwortung für ihre Handlungen mit LLM-Agenten diffundieren, ist seit einiger Zeit zu beobachten: Sowohl die Unternehmen, die LLM-Agenten bereitstellen, als auch diejenigen, die sie nutzen, entbinden sich von der Verantwortung für ihre Handlungen. OpenClaw beschleunigt diesen Prozess noch weiter. Das Versprechen lautet:
Die KI, die tatsächlich Dinge erledigt.
Leert Ihren Posteingang, versendet E-Mails, verwaltet Ihren Kalender, checkt Sie für Flüge ein.
Alles über WhatsApp, Telegram oder jede andere Chat-App, die Sie bereits nutzen.
OpenClaw wurde von Peter Steinberger, einem österreichischen Softwareentwickler, vibe-codiert. [27] Er ist stolz darauf, Code zu veröffentlichen, den er nie gesehen oder überprüft hat [28] und für den er natürlich keine Verantwortung übernehmen möchte: [29]
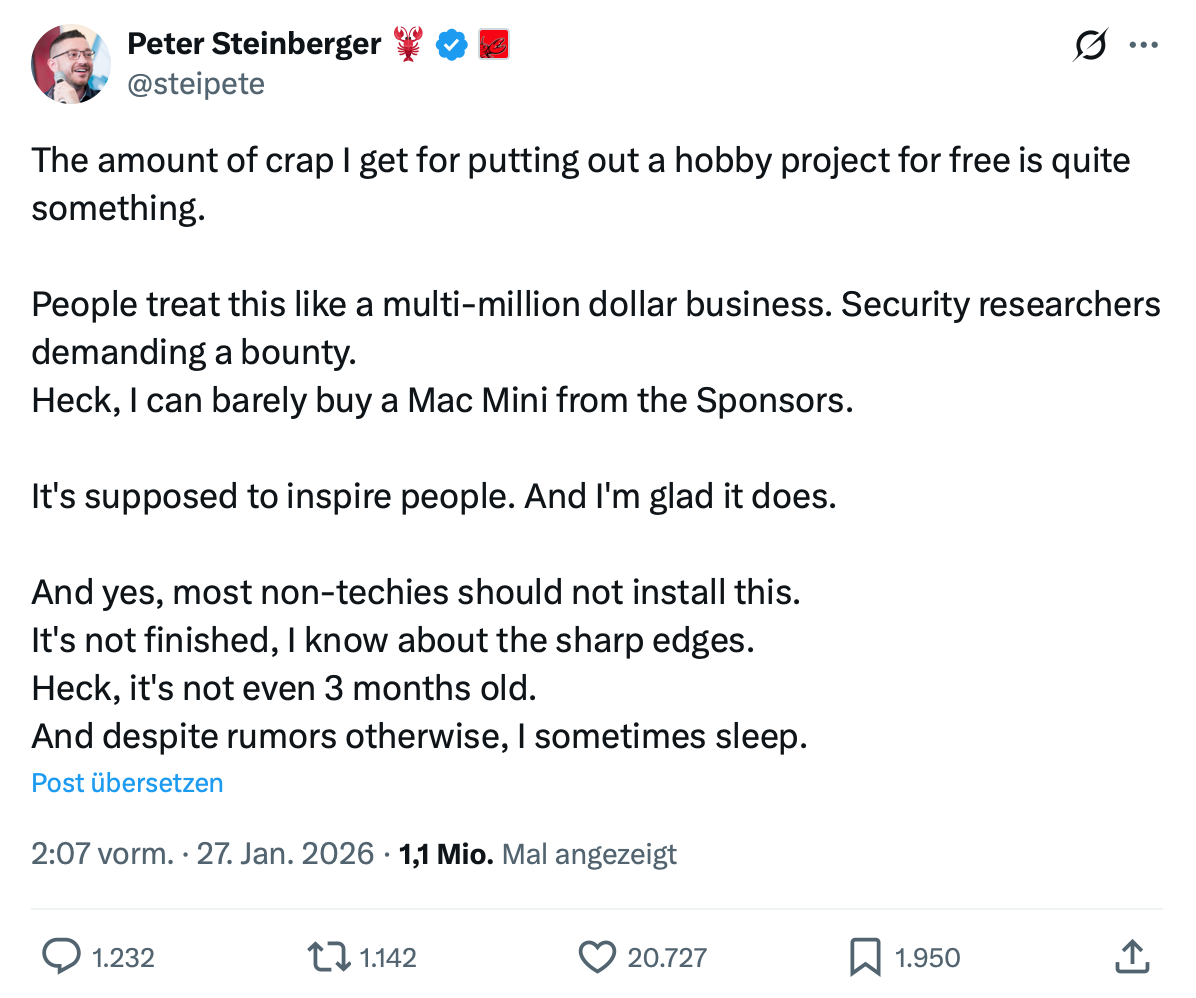
Er ist jedoch kein Einzelfall. Viele LLM-Agenten sind ebenfalls kostenlos verfügbar, neigen jedoch dazu, sich ihrer Verantwortung zu entziehen. Damit schaden sie dem Ruf, den viele Open-Source-Projekte aufgebaut haben. Diese Projekte nehmen die Verantwortung für ihr Produkt, ihre Arbeit und die Sicherheit ihrer Nutzer ernst und haben sich in einigen Fällen über Jahrzehnte hinweg ein hohes Maß an wohlverdientem Vertrauen erarbeitet.
Verwandte Inhalte¶